[기계학습 1] Introduction / 머신러닝 정의
초기 AI (Early AI) 는 사람이하기 힘들지만 컴퓨터는 빨리할 수 있는, 예를 들어 계산이나 검색과 같은 것들을 AI 라고 했다.
지금 현대의 AI (Modern AI) 는 오히려 사람에겐 쉽지만 컴퓨터에게 논리적인 결정 방법들로 설명하기 힘든 것들을 컴퓨터가 할 수 있을 때 AI 라고 한다.
예를 들어 이미지 분류 문제에서 개와 고양이를 구별한다고 하자. 사람에겐 굉장히 쉬운 일이지만 컴퓨터에게 논리적 결정 방법들로 설명하기엔 힘들다. 이런 문제를 컴퓨터가 해결할 수 있다면 AI라고 부르게 되었다.
그렇다면 이제 머신러닝이 무엇인지 정의를 내려보자
머신러닝은 (T, P, E) 이 세가지로 이야기할 수 있다.
T : task / P:performance / E: experience
어떤 컴퓨터프로그래밍이 Experience (경험), 컴퓨터로 치면 데이터로 부터 무엇을 배우는데 task T 와 performance P 를 배운다고 할 수 있다. task T를 측정할 때 performance P를 통해 측정할 수 있는데 이는 데이터 E 를 통해 향상될 수 있다.
Definition: A computer program is said to learn from experience E with respect to some class of tasks T and performance P, if its performance at tasks in T, as measured by P, improves with experience E. (Mitchell, 1997)
기존 규칙 기반 시스템에서는 데이터가 많다해서 성능이 좋아지고 데이터가 없다고해서 성능이 떨어지지는 않는다. 데이터에 따라 성능이 달라지지 않기 때문에 머신러닝이라고 하기엔 힘들다.

Data-driven 머신러닝 시스템에서는 데이터가 많아질 수록 데이터와 아웃풋사이의 관계를 설명하기 쉽기때문에 머신러닝이라고 할 수 있다.
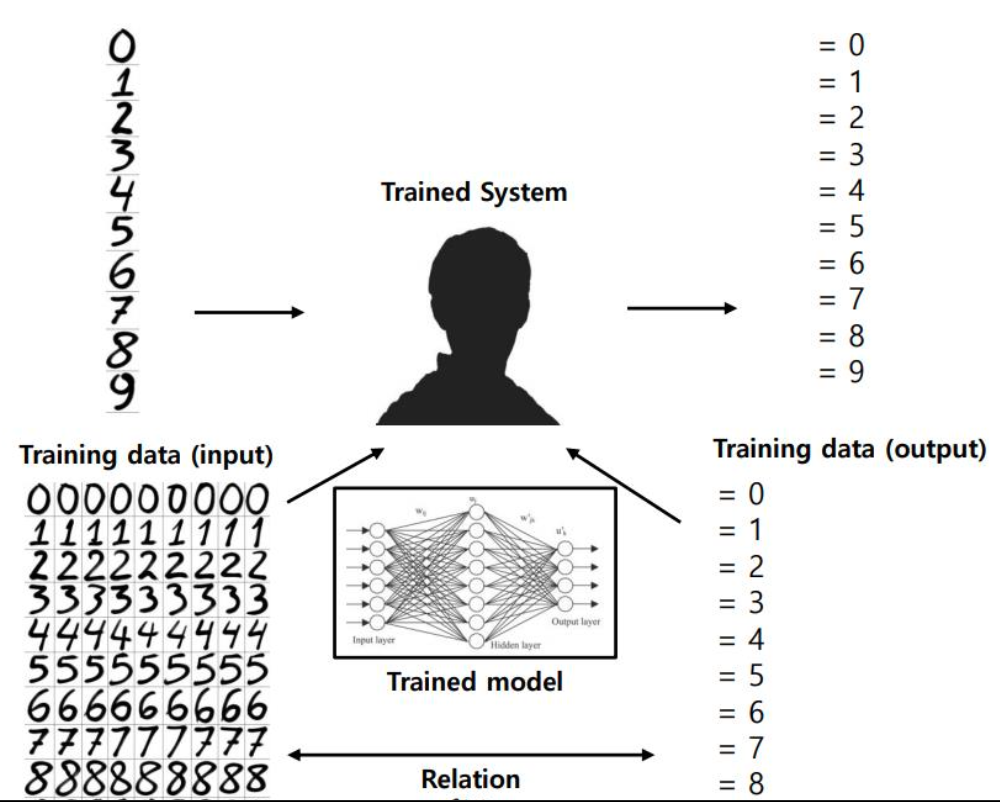
정리하면 머신러닝은 데이터를 통해 인풋과 아웃풋의 관계를 정의할 수 있다면 머신러닝이라고 할 수 있다.

Task T
머신러닝에서
학습은 태스크를 수행하는 능력을 키우는 것이다. 각각의 데이터(Example: 하나하나의 예시들, 정량적으로 측정될 수 있는 feature 들의 모음 )를 처리하는 방법을 배우는 것이 학습이다.
머신러닝 task들의 종류에는 Supervised learning, Unsupervised learning, Reinforcement learning 등이 있다.

1. Supervised learning (지도 학습)
- Classification, Regression
지도학습은 인풋으로 데이터와 데이터에 해당하는 아웃풋을 넣어 기계를 학습시킨다.
Classification 은 0인지 1인지 / 고양이인지 개인지 / True 인지 False 인지 / Male 인지 Female 인지 처럼 A 와 B 중 어떤 것인지를 분류하는 문제이며 그렇기에 불연속적인 값을 지니게 된다. (Categorical target values를 가짐 )
두 가지중 하나로 분류하는 문제도 있지만(binary) / 0~9 중에 하나가 무엇이냐(예를들어 아웃풋 3) 와 같은 multi-class 분류 문제도 있으며 / 0-9 중에 여러개가 무엇이냐(예를 들어 아웃풋 0,3,8) 와 같은 multi-label 분류 문제도 있다.


반면, Regression 은 예를 들어 "우리 아이 키가 언제 클까요" 예측하는 것에 가깝다. 그래프 상에서 현재 아이 키와 성장세를 고려해 미래의 키를 예측하는 문제이다. 그렇기에 연속적인 값을 지니게 된다.



2. Unsupervised learning ( 비지도 학습)
- Clustering
Clustering 은 주어진 데이터들의 특성을 고려해 데이터 집단을 정의하고 데이터 집단의 대표할 수 있는 대표점을 찾는 것으로 데이터 마이닝의 한 방법이다. 인풋으로는 데이터가 들어간다.
(target variable 따로 없음)

3. Reinforcement learning ( 강화 학습 )
리워드를 최대로 얻기 위해선 어떻게 해야 하는 지에 관한 태스크이다.


performance P
알고리즘의 performance 는 정량적으로 측정할 수 있어야 한다. 그리고 태스크 T에 따라서 정의되어야한다. 각 태스크에 걸맞는 퍼포먼스가 있다. 예를 들어 Regression 은 연속적인 값을 가지기 때문에 실제값과 예측값의 차이를 구해야한다. 가장 많이 쓰는 방식으로는 Regression 에서 Mean square error 가 있다. MSE 는 오차의 제곱의 평균이다.

Classificaion 의 performance 평가 지표에는 Accuracy(정확도), Precision (정밀도), Recall(재현도), F1-score 네가지 가 있다.
평가 지표를 알기 전에 먼저 알아야할 것이 있다.
confusion matrix (오차행렬) : Traing 을 통한 Prediction 의 성능을 측정하기 위해 실제 값과 예측값을 비교하기 위한 표이다.


정확도란 모델이 바르게 분류한 비율을 의미한다. 정밀도란 모델이 Positive 로 분류한 것 중 실제값이 Positive 인 비율을 의미한다.

재현도는 실제 Positive 중 모델이 Positive 로 분류한 비율을 말한다. F1-score 은 Precisionr과 Recall의 조화평균으로 데이터가 불균형할 때 사용된다.
성능 평가를 위해선 새로운 데이터를 통해 성능을 평가한다. 이 데이터를 테스트 데이터라고 하는데 초기의 데이터셋에서 훈련 데이터와 테스트 테이터를 초반에 나눈 후, 훈련 데이터로 모델을 훈련시킨 후 테스트 데이터로 테스트를 실시한다.
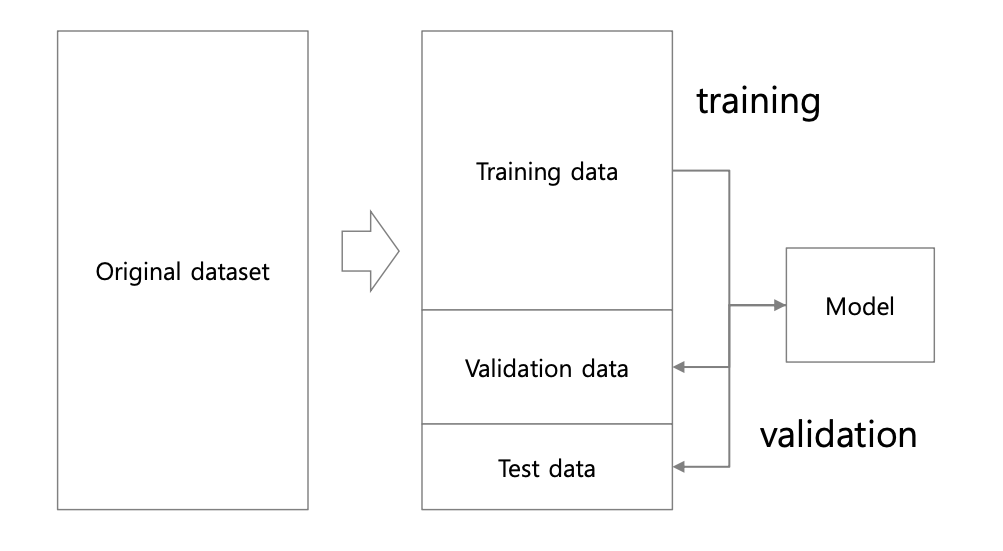

Experience E
전체 데이터셋을 의미한다. 데이터셋은 많은 examples 들의 집합이다.
각각의 데이터는 feature 들로 분류하여 행렬로 나타낼 수 있다. 이 행렬을 design matrix 라고 한다.


• Unsupervised vs. Supervised
- Unsupervised: x → 𝑝(x)
- Supervised:x,y→𝑝(y|x)

Generalization
머신러닝의 주요과제는 새롭게 주어진 테스트 데이터를 어떻게 잘 수행할 수 있는가이다.
이를 측정하기 위해
Trainig performance (트레이닝 데이타에 대한 수행능력)
와 Test preformance (테스트 데이터에 대한 수행능력) 를 각각 계산한다.

예측 모델을 만들때 다음과 같이 선형일 수도 약간 곡선일수도 더 곡선일 수도 있다. 파라미터의 개수가 증가할 수록 트레이닝 데이터에는 더 잘 맞는다는 것을 알 수 있다.
그런데 트레이닝 데이터에 잘 맞으면 좋은 모델이라 할 수 있을까?
만약 트레이닝 데이터에 딱 맞는다면 테스트 데이터로 새로운 데이터가 들어오면 잘 안맞을 수도 있다.
모델 캐패시티는 파라미터, 즉 차수라는 뜻이다.
모델 캐패시티에 따른 그래프의 모양을 잘 살펴보자.

만약 캐패시티가 늘어나면 Overfitting 이 발생할 수 있다. 트레이닝 데이터에 너무 딱맞는 상황이다.
캐패시티가 적어도 underfitting 이 될 수 있다 . 이는 제대로 예측하지 못하는 모델이다.
적절한 캐패시티의 모델을 찾아야한다.


이에 대해 일반화를 해보면
만약 캐패시티가 늘어나면 트레이닝 에러는 줄어들게 된다. 다만 generalization error 는 늘어난다. 만약 캐패시티가 줄어들면 underfitting 존에 진입하여 training error 가 늘어나고 generalization 은 조금 감소한다.
따라서 이 Generalization error 가 적은 적절한 캐피시티를 찾아야한다.

이에대한 No Free Lunch (NFL) 이론이 있다.
이것은 모든 문제에 대해 월등한 올바른 머신러닝 모델은 없고 각 장단점이 있다는 뜻이다. 그러니 최적의 모델을 잘 선택해야한다.
weight decay
테스트 에러를 낮추는 편이 일반적인 성능을 확인할 수 있고 이를 위해 오버피팅이 되지 않아야한다. 그렇게 하기 위해선
모델 캐패시티를 바꿔가면서 학습시키기 보다는 충분히 큰 캐피시티의 모델에서 규제를 가하는 편이 더 낫다.