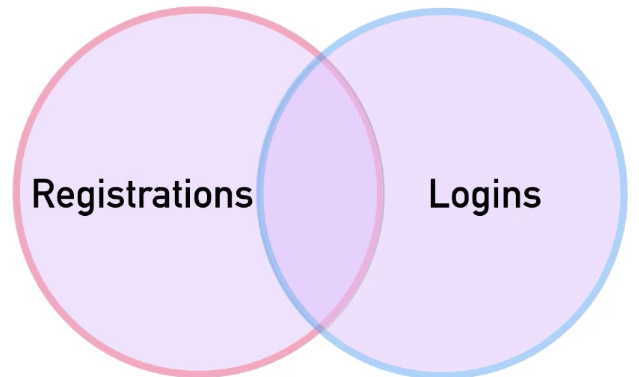
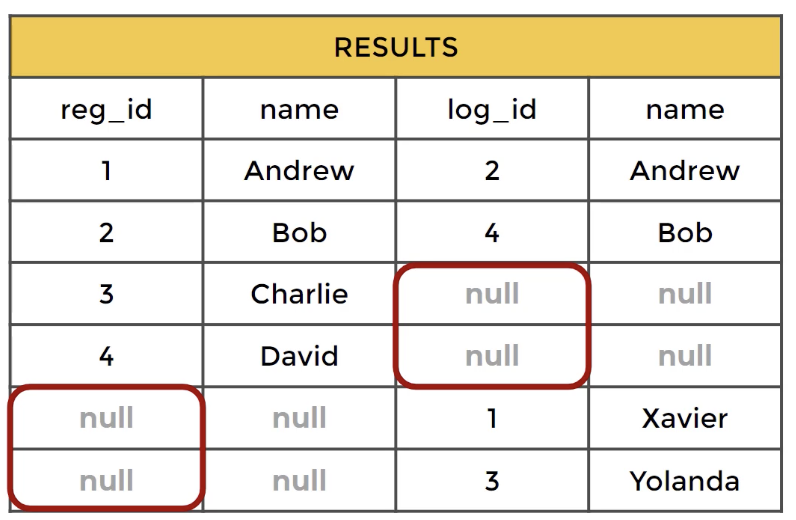
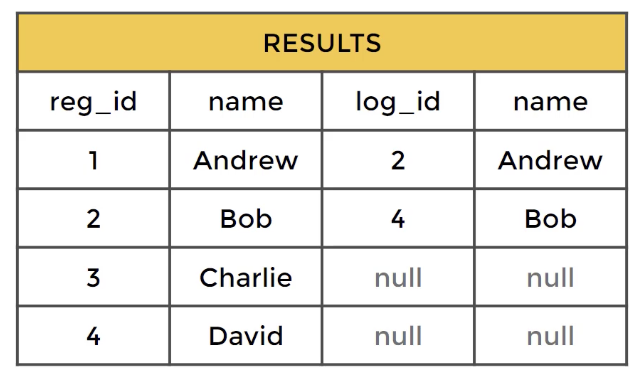
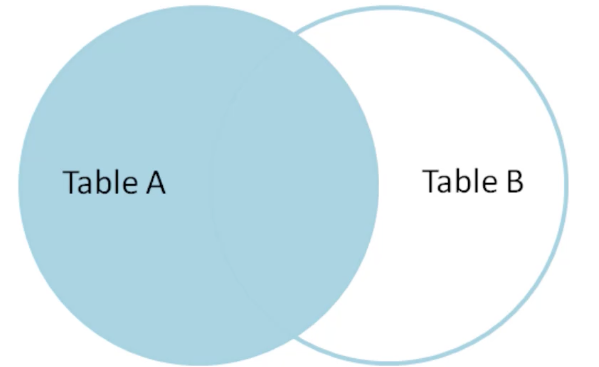
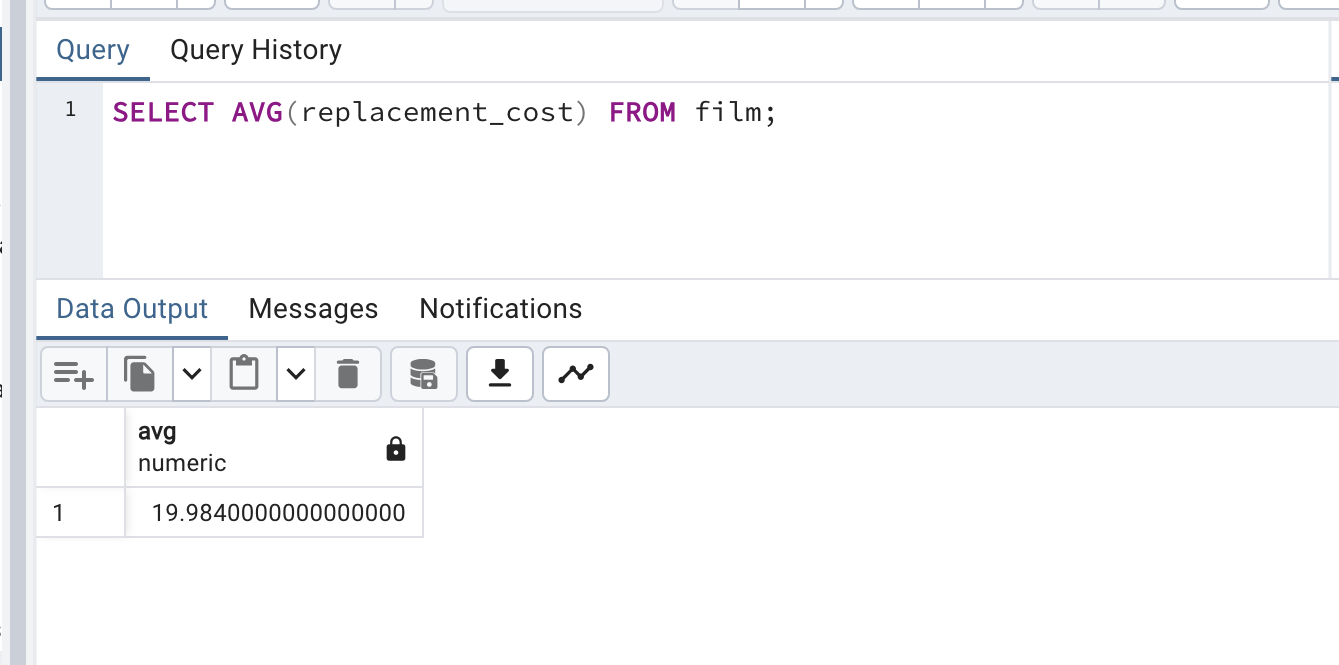
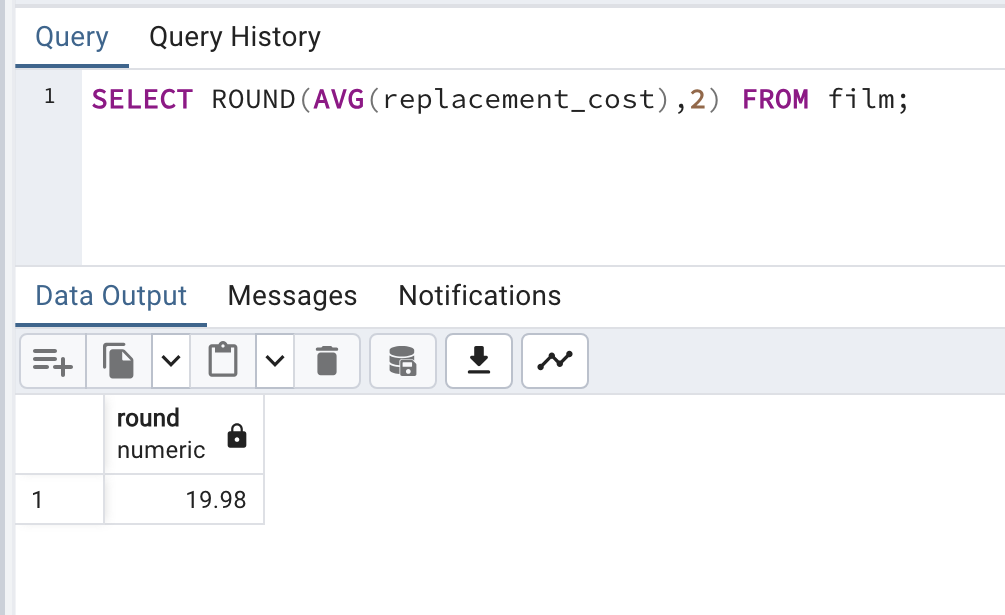
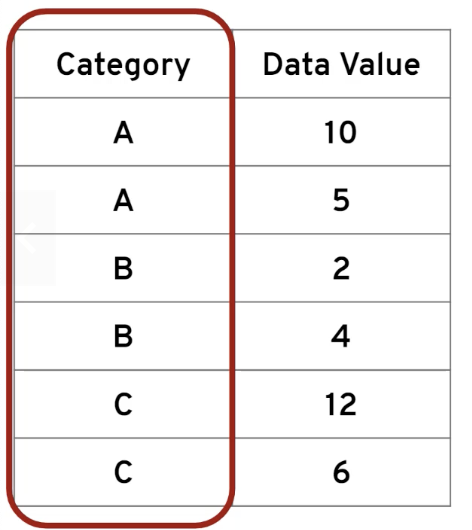
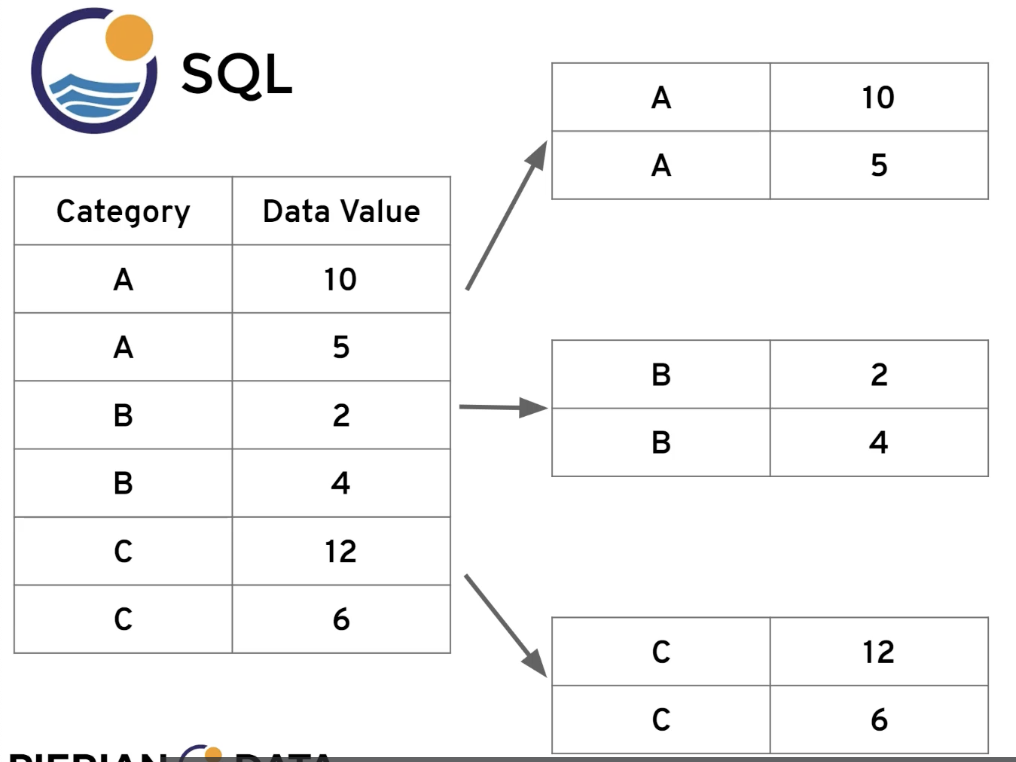
해당 포스트는 Udemy 'The Complete SQL Bootcamp: Go from Zero to Hero' 를 보고 작성한 내용입니다.
데이터베이스?
데이터베이스는 사용자가 데이터를 체계적으로 구성, 저장, 관리할 수 있게 해주는 시스템이다. 대량의 데이터를 효율적으로 처리하고, 다양한 사용자와 애플리케이션의 요구를 충족시키는 데 있어 핵심적인 역할을 한다.
데이터베이스는 다양한 사용자가 있을 수 있다. 마케팅 분석가, 영업 운영 분석가, 데이터 과학자, 웹 개발자, 소프트웨어 엔지니어 등 광범위한 분야의 전문가들이 데이터베이스를 활용함으로써, 복잡한 데이터 관리 작업을 보다 효과적으로 수행할 수 있게 된다.
웹사이트와 애플리케이션에서의 데이터베이스
현대의 웹사이트와 웹 애플리케이션, 모바일 애플리케이션은 대부분 데이터베이스와 연결되어 있다. 사용자의 정보를 저장하고, 콘텐츠를 관리하며, 다양한 서비스를 제공하는 데 데이터베이스가 핵심적으로 사용된다.
데이터베이스와 스프레드시트
일반 사용자는 대부분 엑셀이나 스프레드시트를 통해 데이터를 다루는 경험이 있을 것이다. 이러한 도구들은 비전문가도 데이터를 쉽게 처리할 수 있게 해주는 장점이 있다. 하지만 데이터의 규모가 커지고, 데이터 무결성이 중요한 상황에서는 데이터베이스가 훨씬 적합하다. 데이터베이스는 무결성을 유지하며, 허가된 사용자만 데이터를 변경할 수 있도록 관리할 수 있기 때문이다.
데이터베이스 플랫폼 선택
여러 데이터베이스 플랫폼 중에서 PostgreSQL, MySQL, MariaDB, MSSQL Server Express, Microsoft Access, SQLite 등이 널리 사용된다. PostgreSQL은 무료(오픈 소스)이며, 멀티 플랫폼에서 널리 사용되는 경우에 주로 선택된다. 이번 강의에서도 PostgreSql 을 사용할 예정이다.
SQL
SQL(Structured Query Language)은 데이터베이스와 소통하는 데 사용되는 프로그래밍 언어이다. 데이터를 조회, 수정, 삭제 등의 작업을 수행할 수 있게 해주며, 데이터베이스 관리의 기본이 된다.
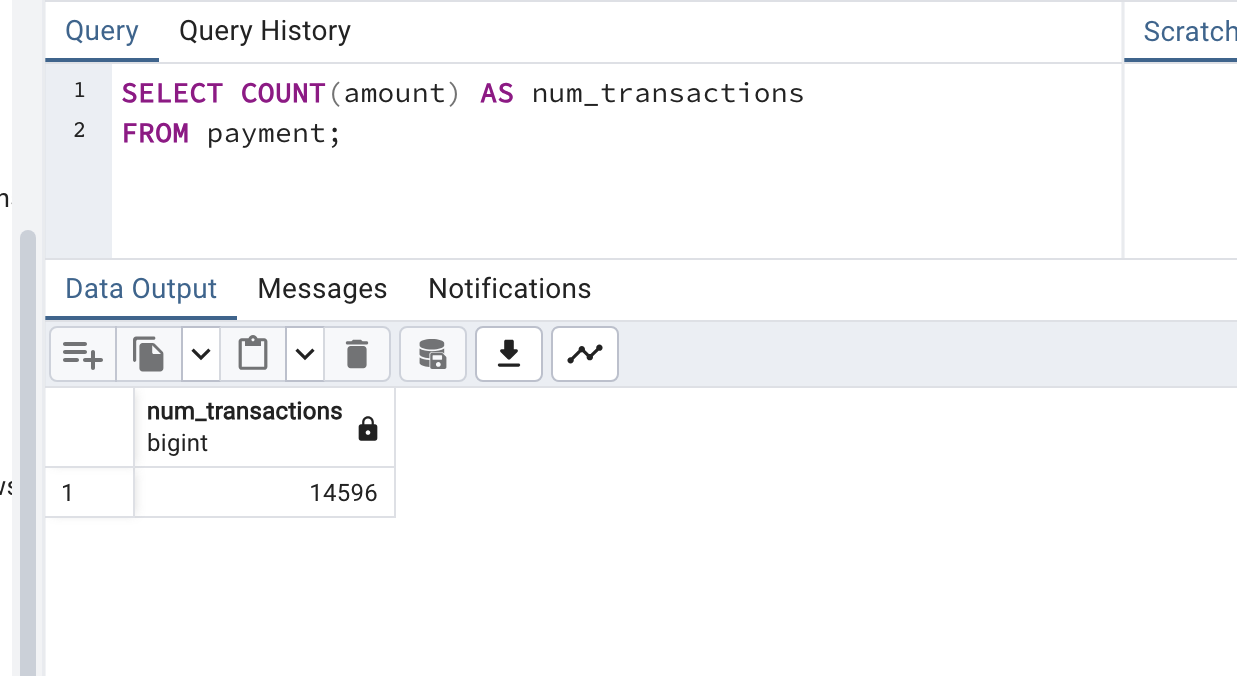
SQL 예시
이 SQL 쿼리는 sales 테이블에서 고객의 ID, 이름, 성을 선택하고, 이름 순으로 정렬한다.
SELECT customer_id, first_name, last_name
FROM sales
ORDER BY first_name;
Mac 에서 PostgreSQL 설치하기
PostgreSQL 과 PgAdmin 을 설치할 것이다. PostgreSQL 은 SQL 엔진이다. 데이터를 보관하고 쿼리를 읽는 그리고 정보를 반환하는
PgAdmin 은 PostgreSQL 백엔드와 연결하기 위한 GUI 이다.
설치 진행 시 다음 요소들을 기억하자
- 절대 dvdrental.tar 파일을 직접 열지 말자
- PostgreSQL 패스워드를 지정할 것인데 잊지 말고 잘 적어두자.
1.PostgreSQL 다운받기
구글 크롬 브라우저에서 PostgreSQL 입력후 공식 웹사이트에 들어간다.
PostegreSQL 다운로드 버튼을 누른다.

다양한 패키지가 있을텐데 각자의 운영체제에 맞는 것을 설치한다. 나는 macOS 를 클릭하였다.

다음과 같은 패키지, 버전이 있는데 맥 OS 플랫폼이 가지고 있는 PostgreSQL 버전과 일치하는 지 확인해야한다. 내 mac 컴퓨터가 오래된 것이라면 최신의 PostgreSQl 을 다운해도 잘 작동하지 않을 수 있다!

download the installer 클릭 후 버전을 선택하면 된다. 나는 최신버전이라 최신 버전의 PostgreSQL 을 설치하였다.
그러면 압축 파일이 설치될 것인데 이를 풀어준다. 이런 화면이 뜰 것이다.

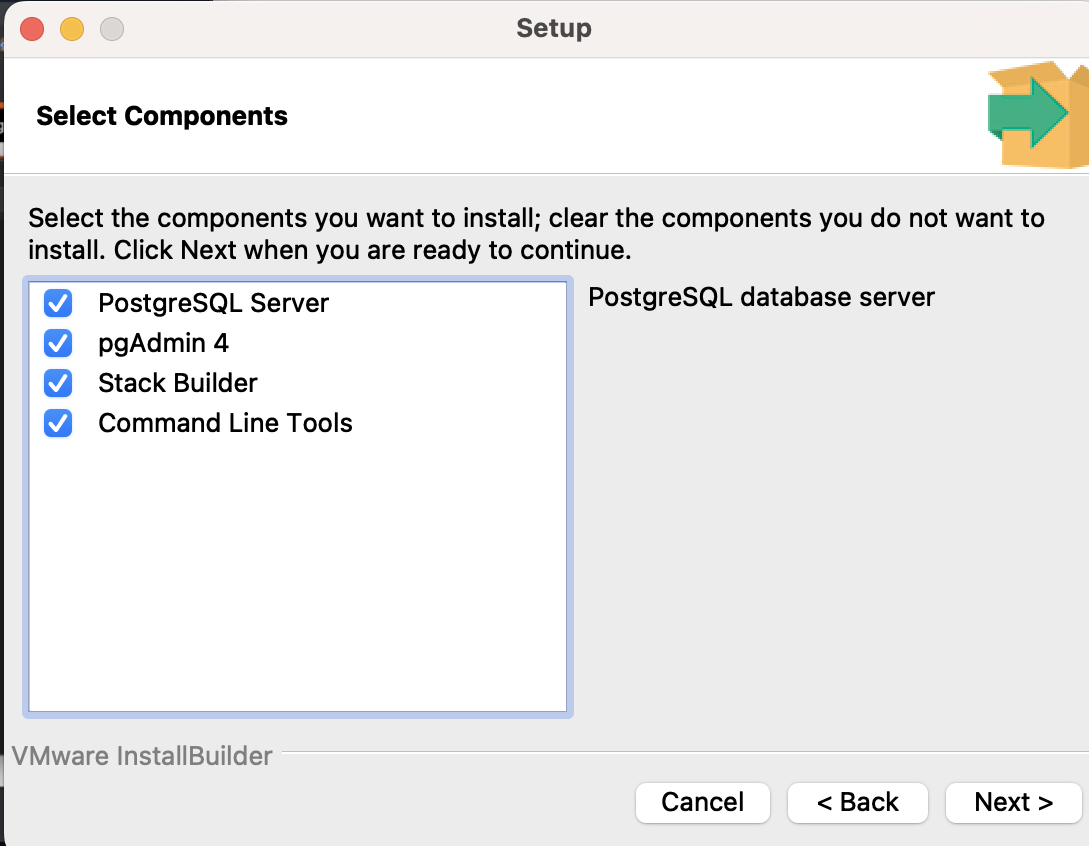
계속해서 다음을 누른다. 아래와 같은 화면에서는 모두 체크된 상태 그대로 다음을 누른다.
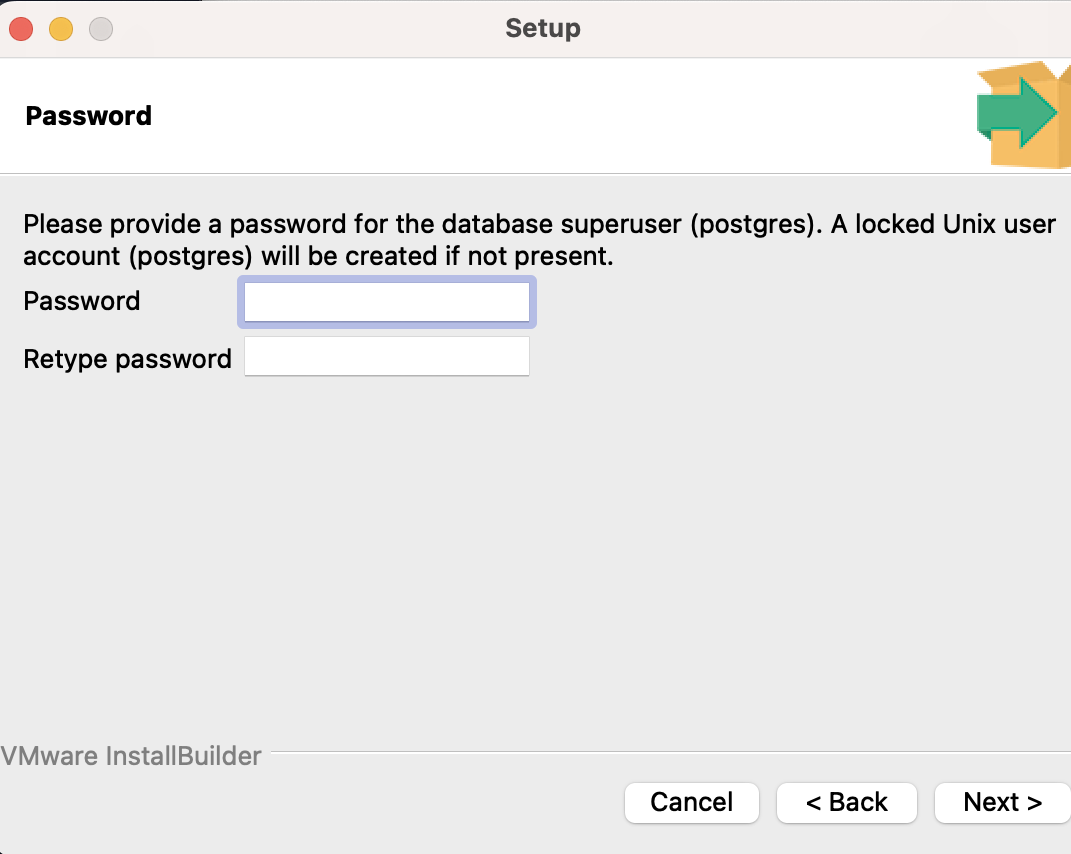
다음으로 암호 입력 창이 뜰 것이다. 무조건 기억할 수 있는 암호를 입력해야한다.
까먹으면 골치 아파질 수도 있다.
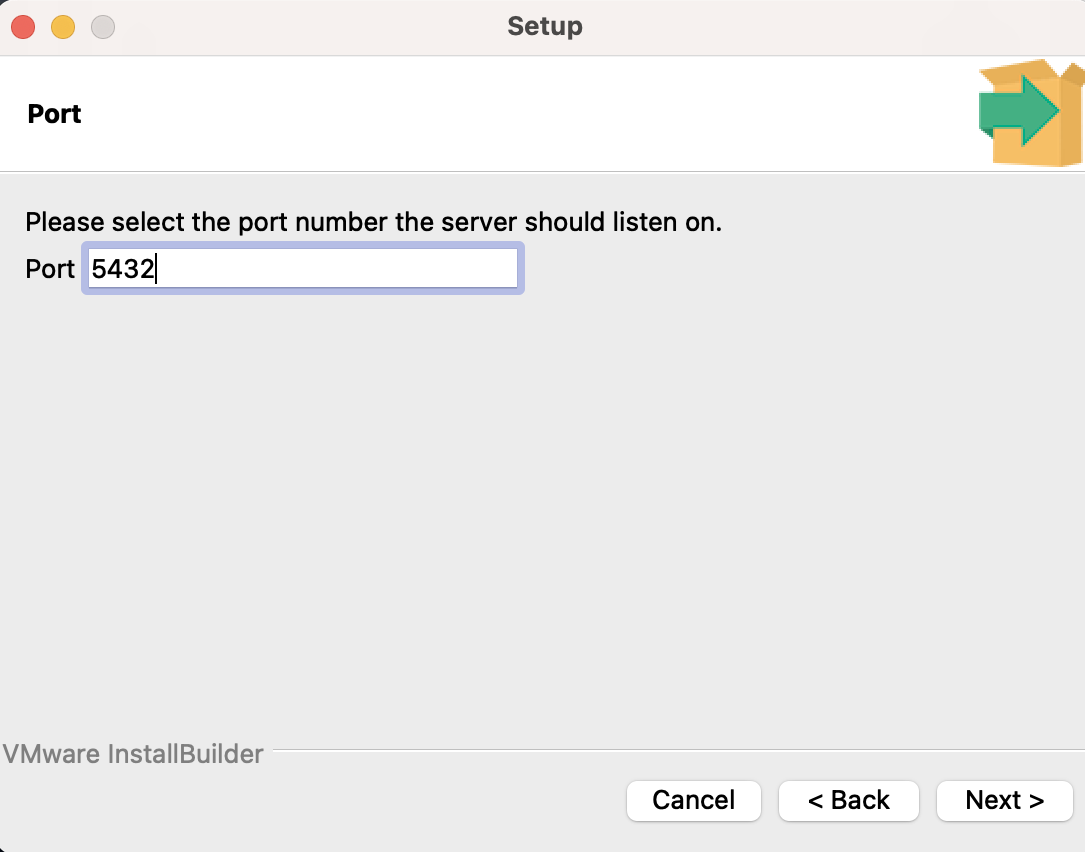
포트 번호를 선택해야한다. 이전에 PostgreSQL 을 설치했는지 여부에 따라 다를 수 있는데 일반적인건 5433 으로 나타난다. 이건 포트가 열려있고 서버가 이를 수신할 수 있음을 의미한다. 이 숫자는 따로 수정할 필요가 없고 next 를 누르면 된다.
다음은 Location 인데 바로 next 를 누르고 계속해서 next 를 누르면 설치가 될 것이다.
설치가 되었다면 Stack Builder 는 클릭 해제 후 Finish 를 누르면 된다.

- PgAdmin 설치하기
PostgreSQL 이 설치되었다면 다음으로는 PGAdmin 을 설치할 것이다. 우선 브라우저로 이동하여 pgadmin 을 구글에 서치한다.
공식사이트에 들어가서 Download 를 클릭한다. 여러 패키지가 있을 텐데 나는 macOS 를 클릭하였다.
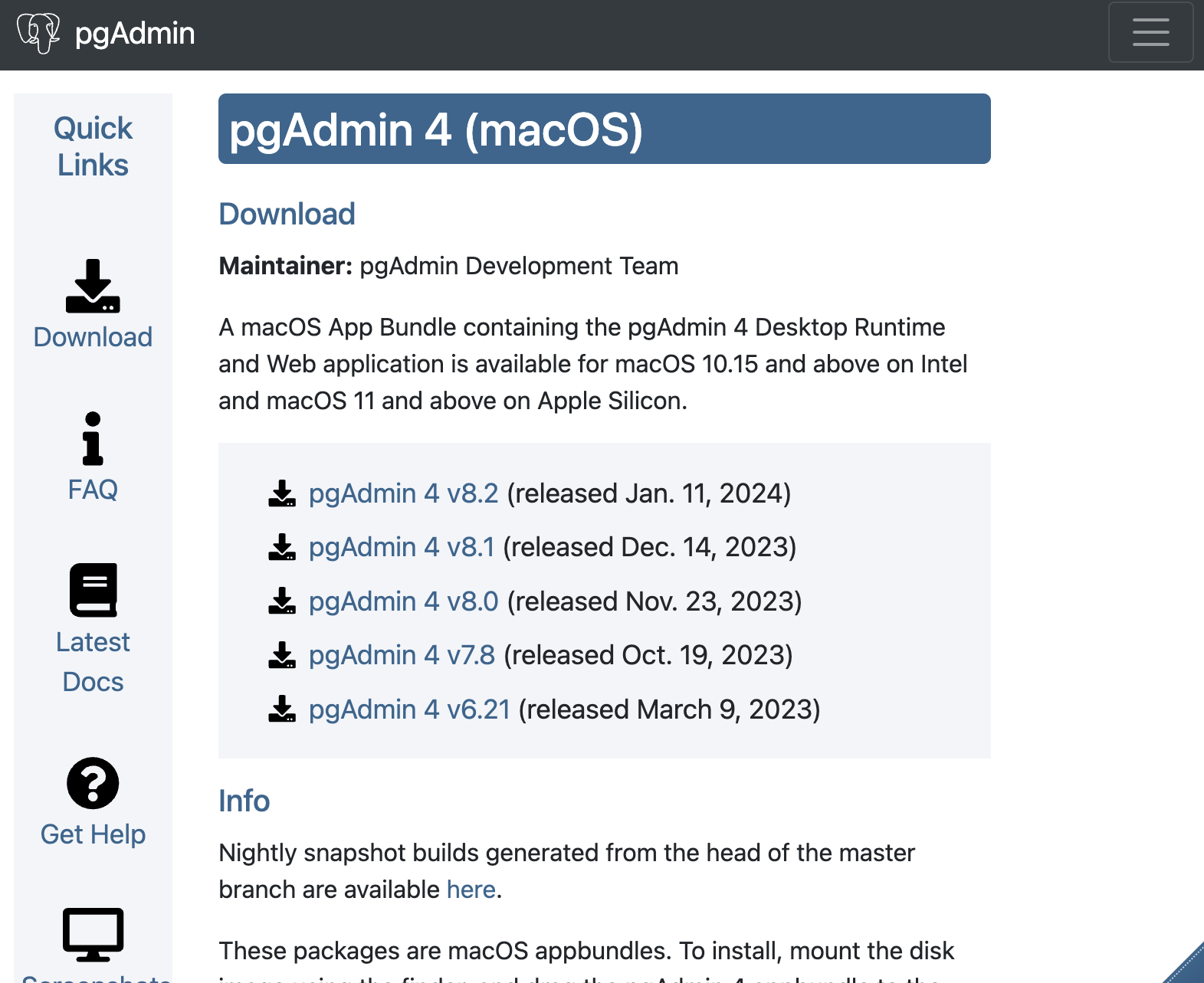
나는 최신 버전의 pgAdmin 4 v8.2 를 클릭하였다.
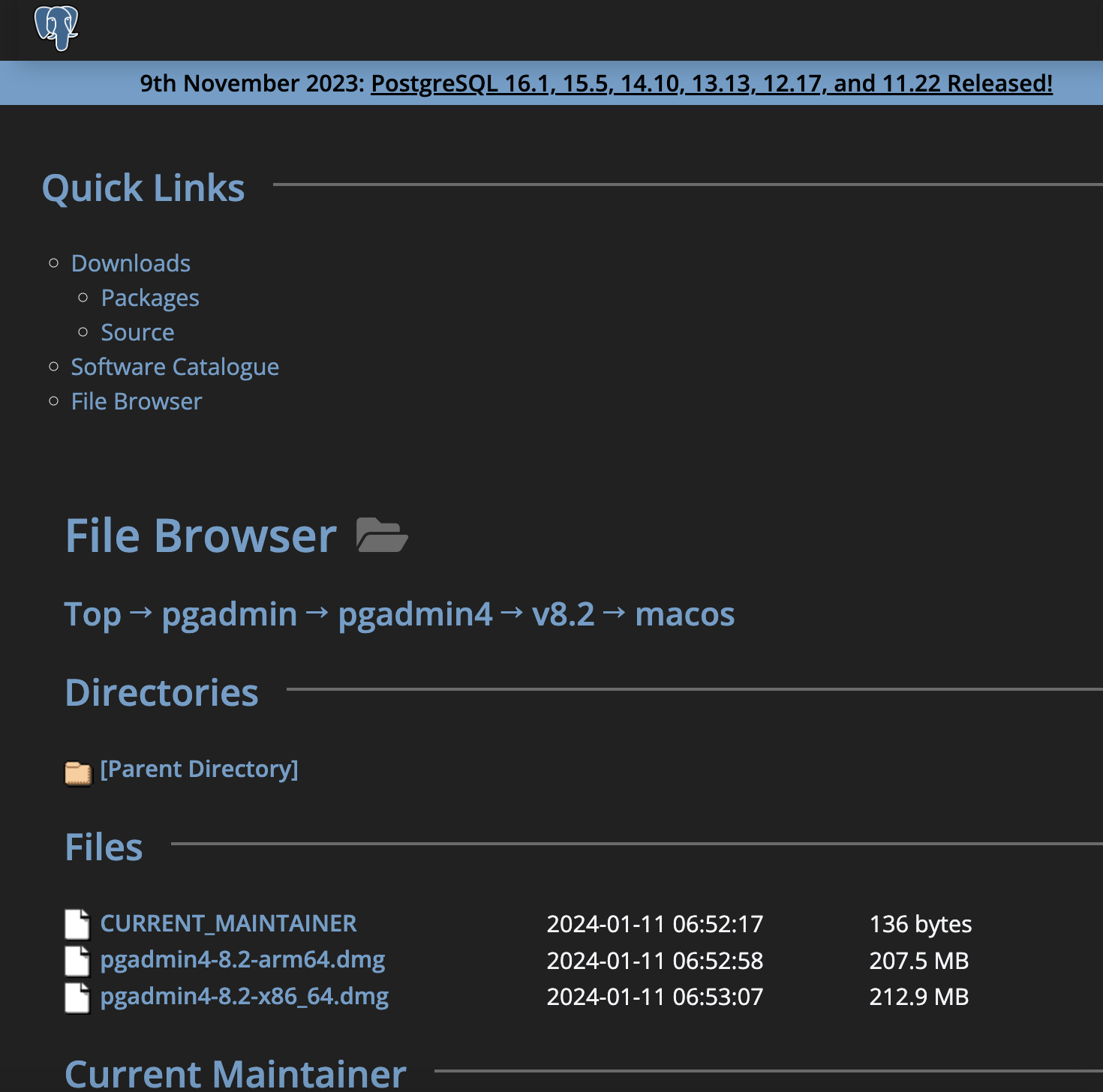
그 후, Files 에 보면 dmg 파일이 있을 건데 자신의 mac 이 arm64인지 x86인지 잘 확인 후 누르면 된다. 나는 arm64를 클릭하였다.
설치된 파일을 클릭한 후, 다음 창이 뜨면 Application 으로 옮겨준다.
이러면 전체 설치 프로세스는 끝이다.
- dvdrental.tar 파일 다운하기(직접적으로 open 하지 않기 주의)
다음 단계는 dvdrental.tar 파일을 다운로드하는 것이다. 주의할 것은 직접 오픈해서는 안된다. 파일 압축을 풀거나 더블클릭하거나 파일을 열거나 이런 상호작용을 하지 않아야 한다. 그저 다운만 하면 된다. dvdrental.tar 파일은 샘플 데이터파일이다. 아래 사이트에서 다운할 수 있다.
dvdrentar.tar 다운받기
- 재부팅하기
제대로 깔렸는지 확인을 위해 컴퓨터를 재부팅한다.
- 데이터베이스를 저장하기(실패한 종료 코드가 표시되면 무시한다.)
재부팅이 되었다면 pgamdin 을 설치한다. 아마 Application 에 있을 것이다.
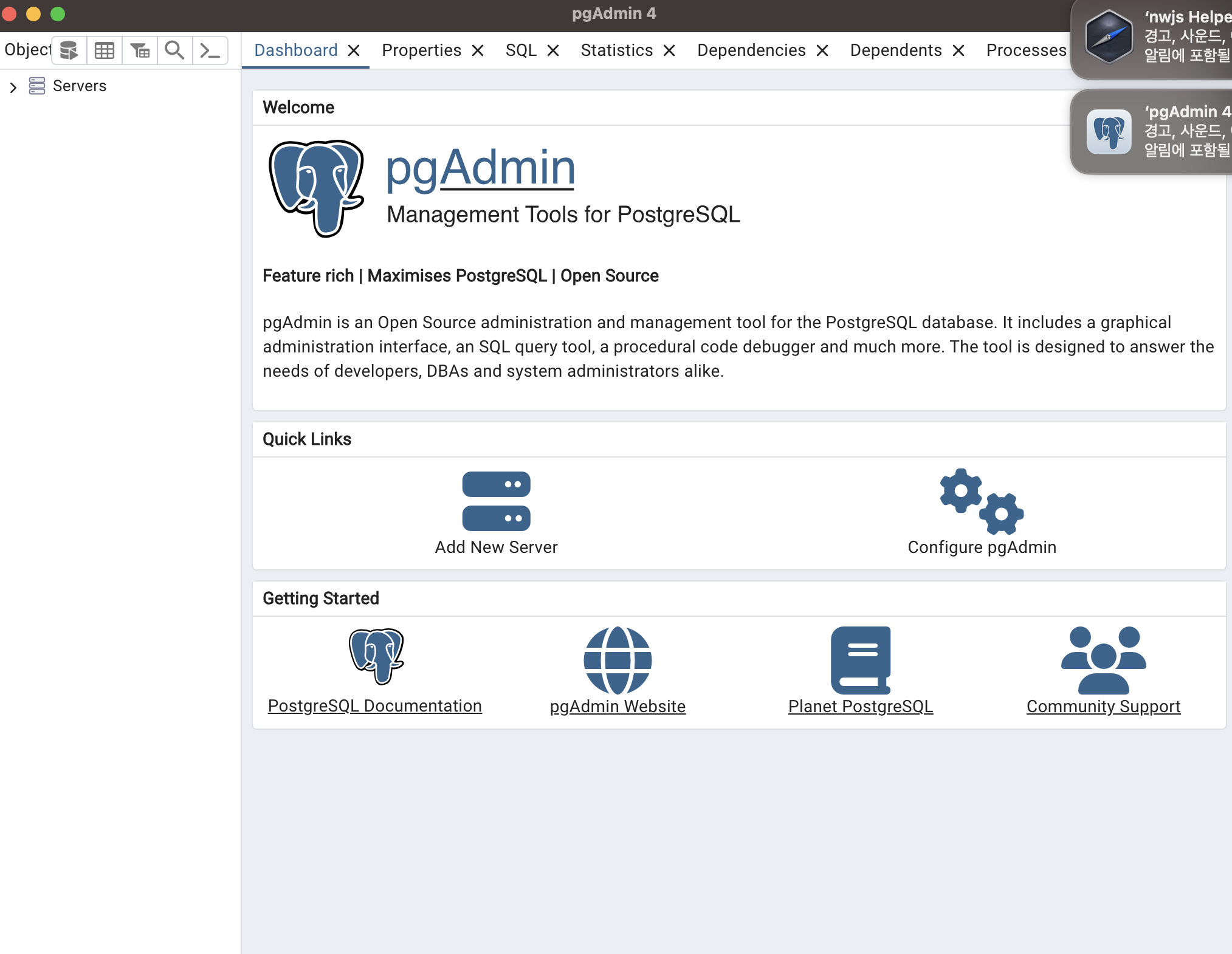
왼쪽에 있는 Server 를 열고 설치한 PostgreSQL 16을 확장하려고 하면 다음같은 비밀번호 입력 팝업창이 뜬다. 이때 아까 지정했던 PostgreSQL 비밀번호를 입력하면 된다.
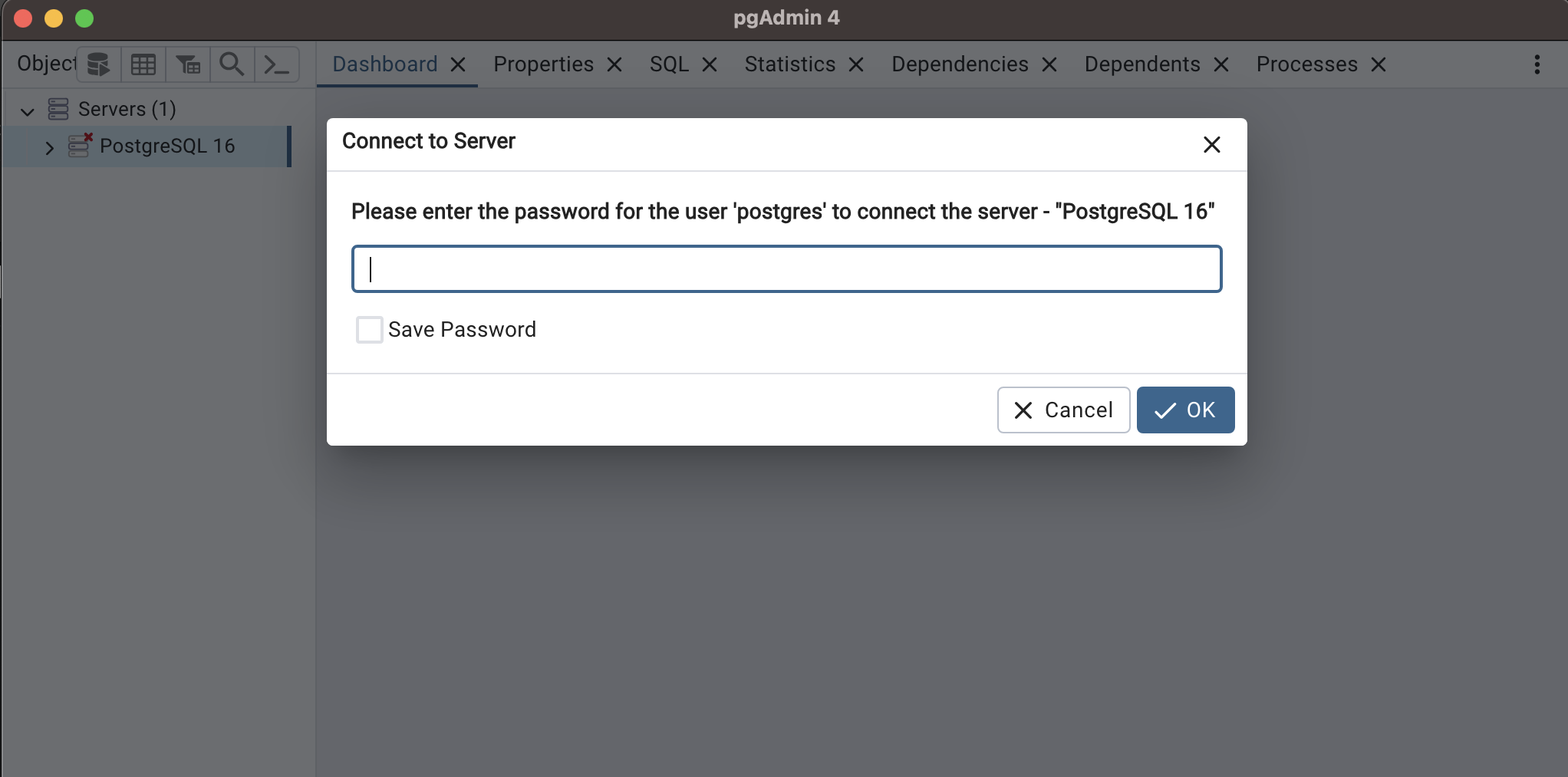
비밀번호를 입력하면 다음과 같은 화면이 뜰 것이다.

데이터베이스를 만들기 위해 왼쪽 탭의 Databases 클릭 후 우클릭을 하여 Create-> Database 를 선택한다. Database 에는 dvdrental 을 입력한다. 그 후 save 를 누른다.
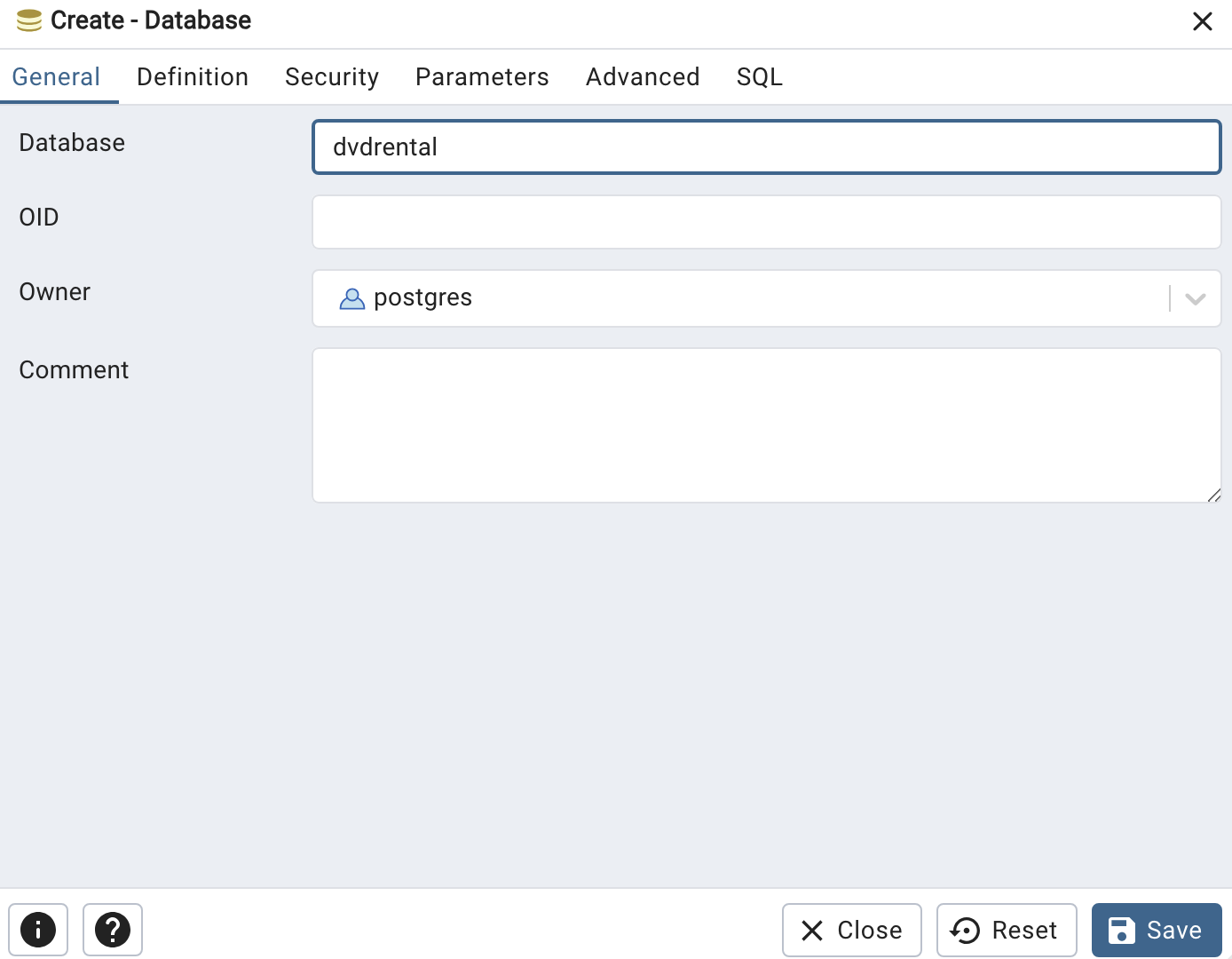
입력됐다면 우리가 아까 다운받은 dvdrental.tar 파일, dvd rental 정보를 실제로 입력할 것이다. 왼쪽의 dvdrental 을 우클릭하여 restore 을 클릭한다.
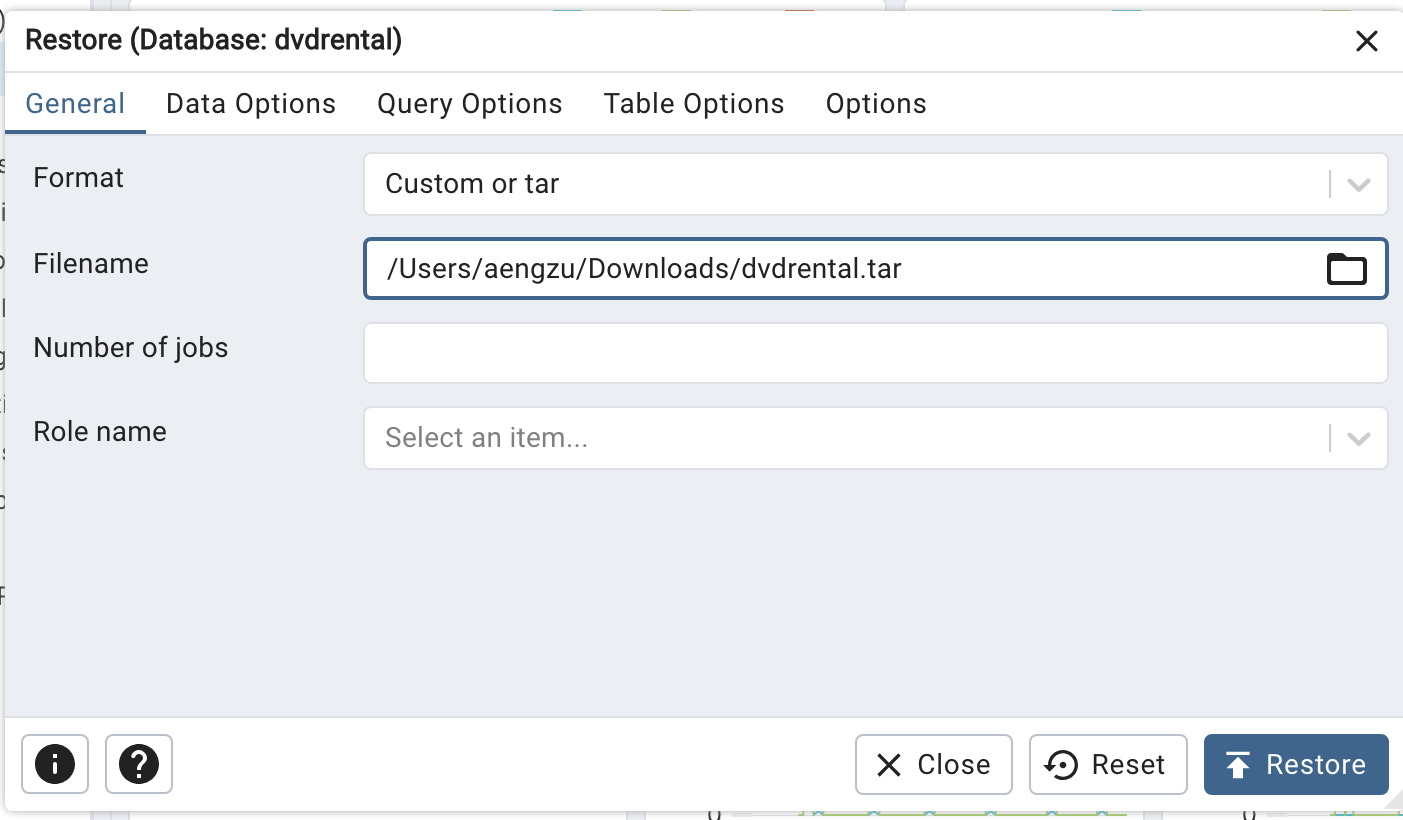
그 후 나온 팝업창에서
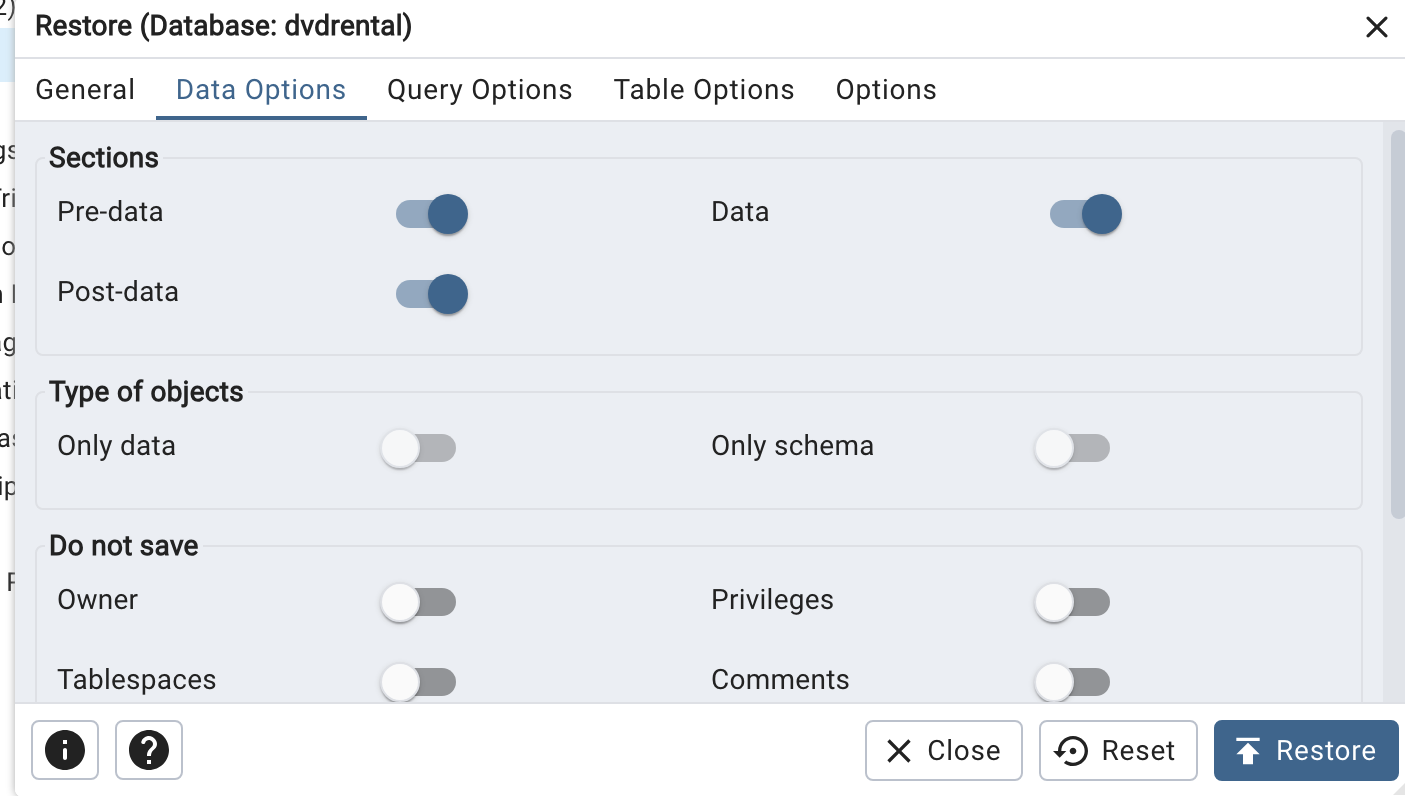
dvdrental.tar 파일의 위치를 적고, Data Option 에서 다음 세 개를 활성화 한 뒤 Restore 을 클릭하면된다.
그런 다음 적용을 위해 dvdrental 우클릭 후 Refresh 를 한 번 눌러주자.
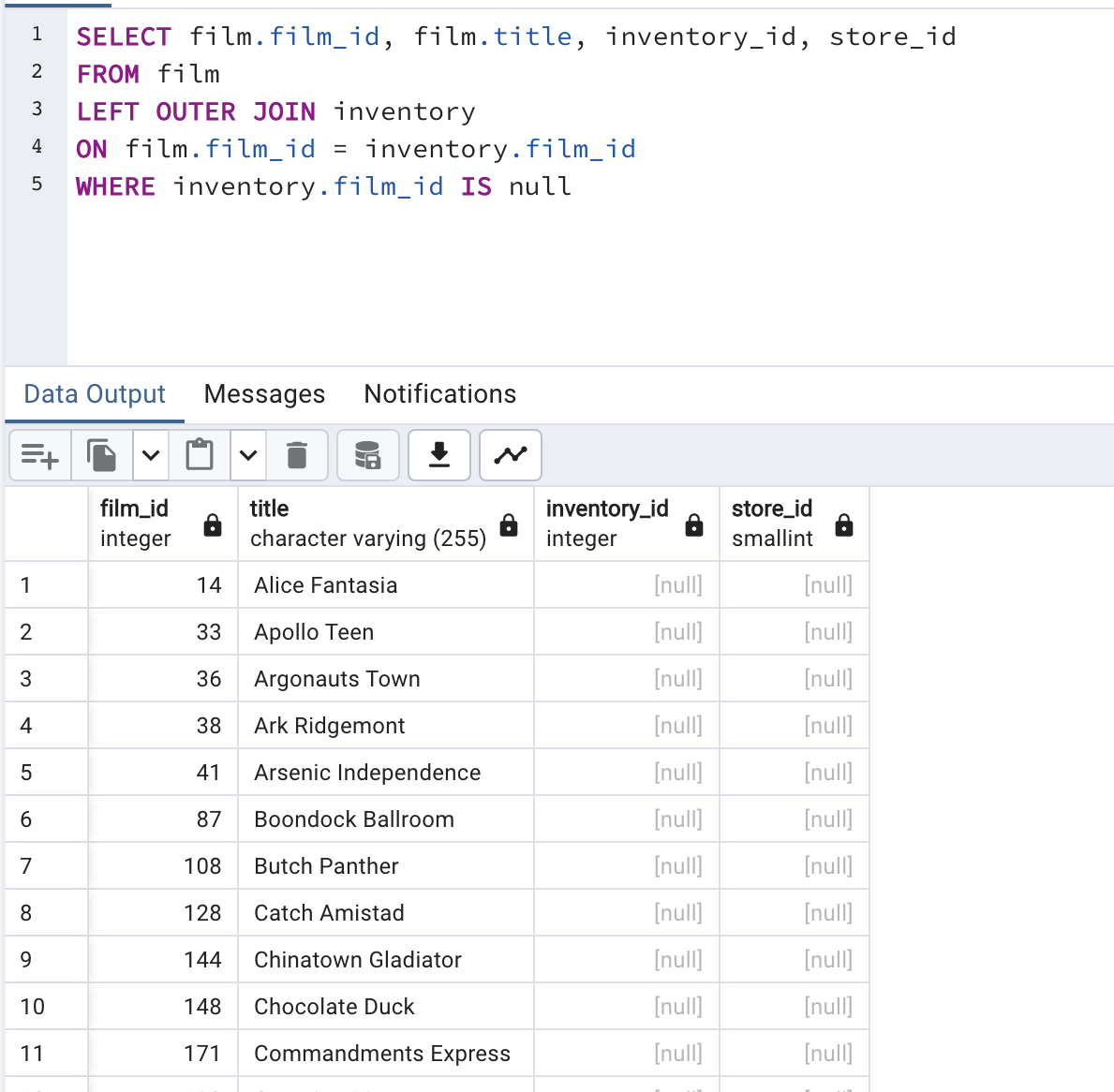
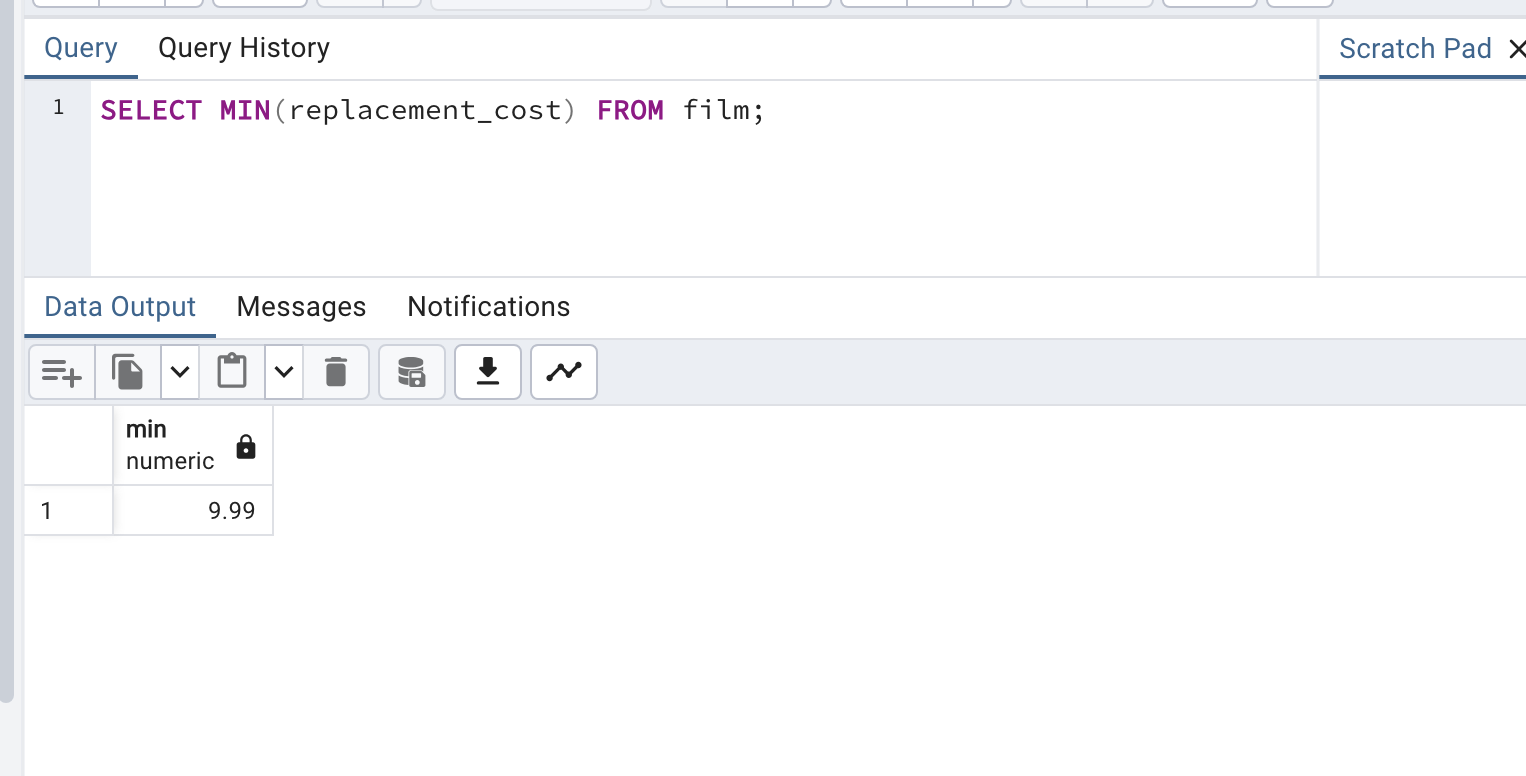
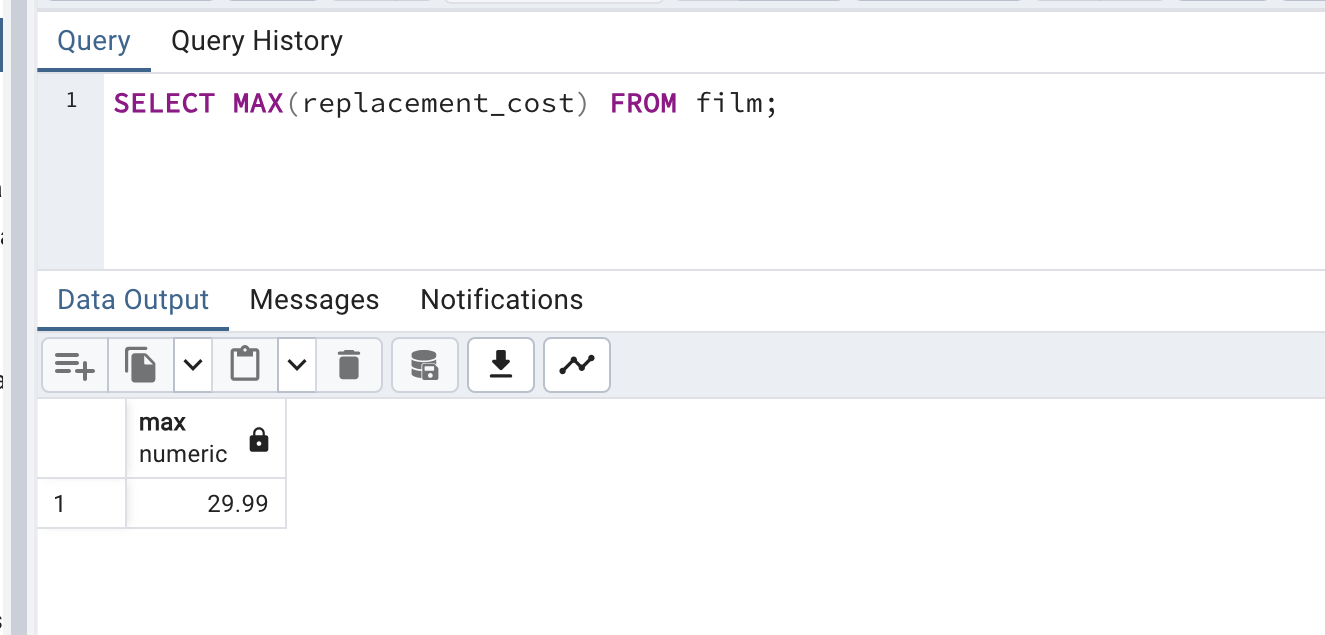
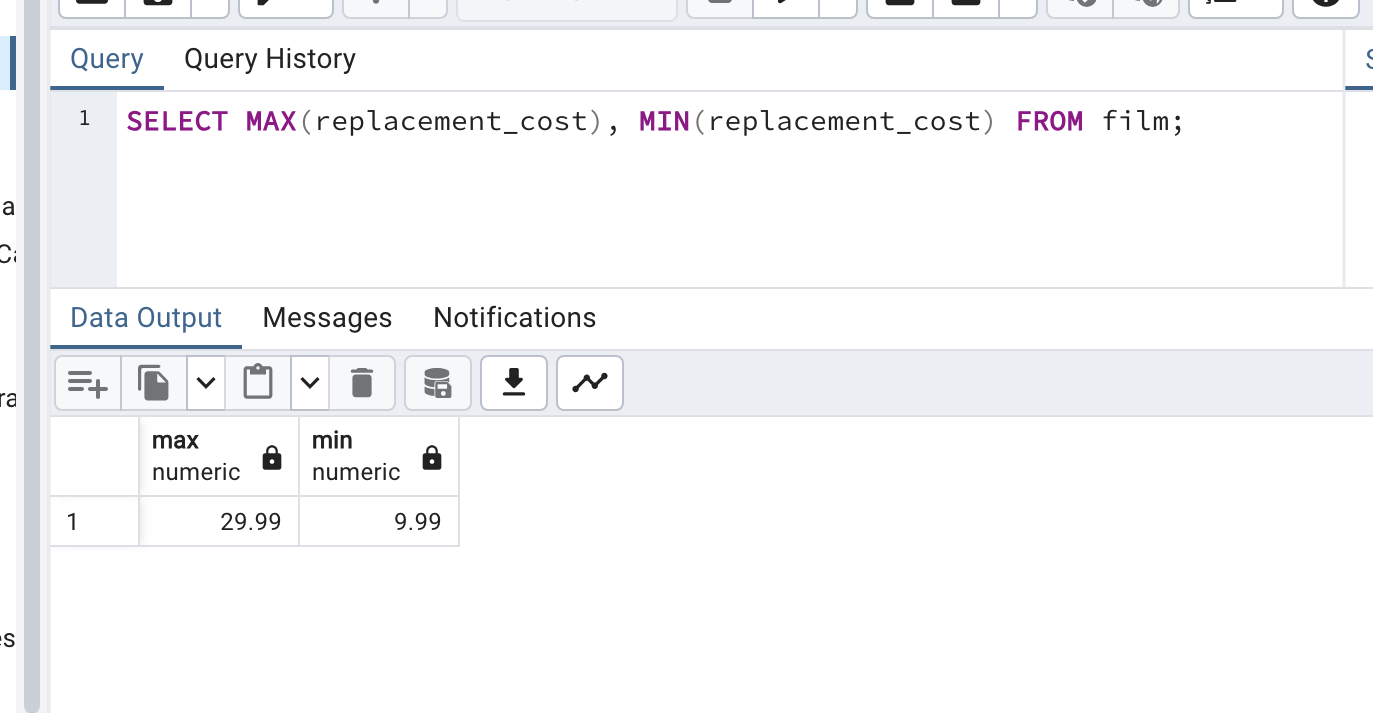
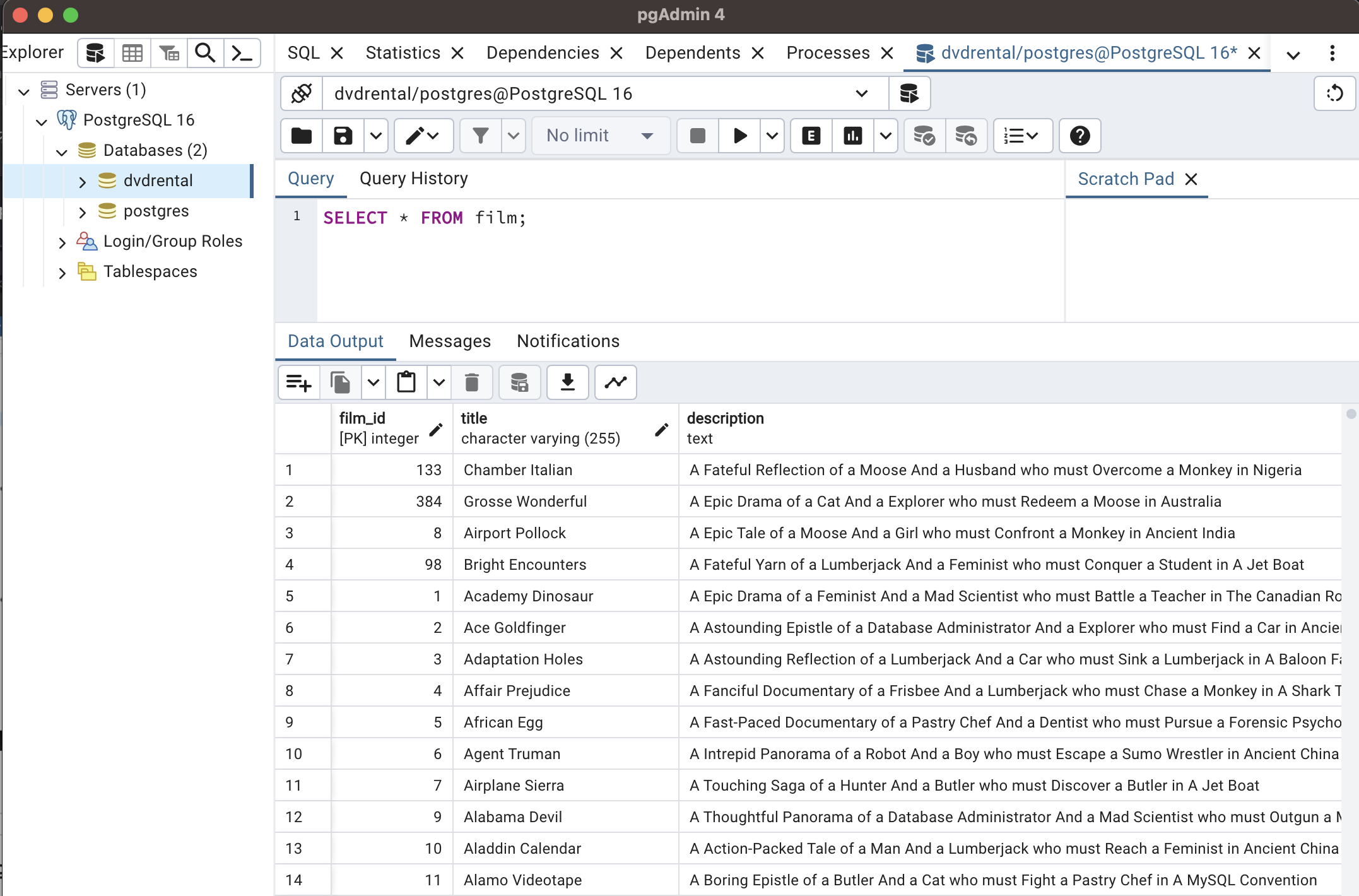
이제 잘 되는 지 확인해볼 것이다. 왼쪽 dvdrental 우클릭 후 Query Tool 을 클릭하면 다음과 같은 Query pad 가 뜰 것이다. 여기서 SELECT * FROM film; 을 입력해보자. 그럼 영화 데이터들을 확인할 수 있다.
SELECT * FROM film;
결론
데이터베이스는 현대 디지털 환경에서 필수적인 요소로, 대량의 데이터를 체계적으로 관리하고 활용할 수 있게 해줍니다. 다양한 분야의 전문가들이 데이터베이스를 사용하여 복잡한 데이터 관리 작업을 수행할 수 있으며, 이는 마케팅 분석부터 소프트웨어 개발까지 광범위한 응용을 가능하게 합니다. 데이터베이스와 스프레드시트는 모두 데이터를 다루는 도구지만, 데이터의 규모가 커지고 무결성이 중요한 상황에서 데이터베이스가 더욱 적합한 솔루션을 제공합니다.
이번 포스트에서는 데이터베이스 플랫폼 중 하나인 PostgreSQL의 설치 과정을 통해 데이터베이스의 기본적인 활용 방법을 살펴보았습니다. PostgreSQL은 무료이며 멀티 플랫폼에서 널리 사용되는 오픈 소스 데이터베이스 시스템으로, SQL(Structured Query Language)을 사용하여 데이터베이스와 소통합니다. SQL은 데이터 조회, 수정, 삭제 등의 작업을 수행할 수 있게 해주며, 데이터베이스 관리의 기본입니다.