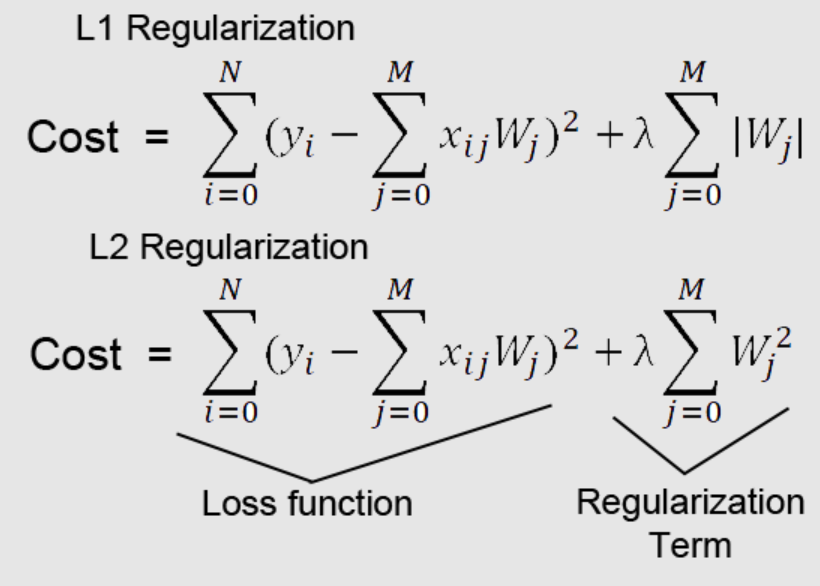
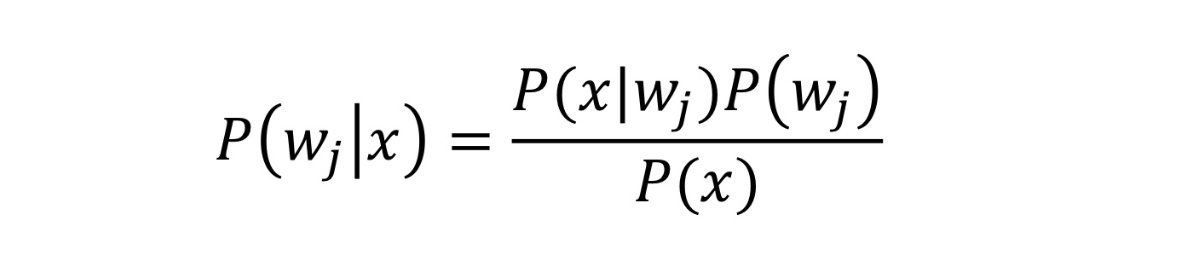Introduction
DecisionTree에는 Classification Tree 와 Regression Tree 문제가 있다.
Classification Tree 는 여자인지 남자인지 개인지 고양이인지를 예측한다.
Regression Tree은 사람의 급여나 외부 온도등을 예측한다.
이번에는 Classification Tree 를 공부할 것이다.
Decision Tree
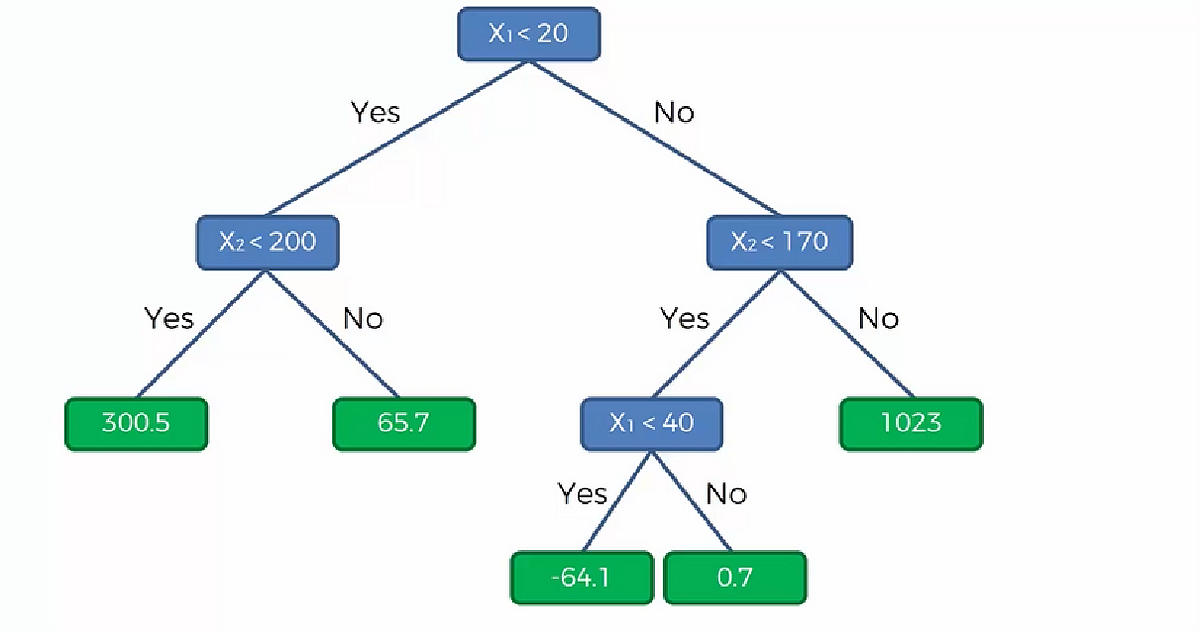
만약 아래같은 데이터셋이있을때 녹색 카테고리와 빨간 카테고리를 분류하는 모델을 만들기 위해 여러 분할을 거치는 ㅓㄱㅅ이다.
여기서는 3번의 분할이 있었다.
첫번째 분할은 X2가 60 보다 이상인 수와 작은 수를 분할하였다.
다음 분할은 X1이 50보다 작은지 큰지를 분할하였다.
다음 분할3은 X1을 70보다 큰지 작은지를 분할하였다.
다음 분할4도 예측할 수 있을 것이다. 저기 녹색과 빨강을 분할할 만한 대략 20 지점에서 분할을 하면 된다.

우리가 겪은 분할 과정을 Decision Tree 로 나타내면 이렇다.

Decision Tree 는 아주 오래된 방법이다. 그래서 최근에는 잘 안쓰이다가 최근에 정교한 방법으로 업그레이드 되어 다시 자주 쓰이게 되었다.
이 업그레이드된 방법에는
Random Forest , Gradient Boosting 등이 있다.
몇몇 알고리즘은 아이폰 페이스인식에도 사용된다.
실습
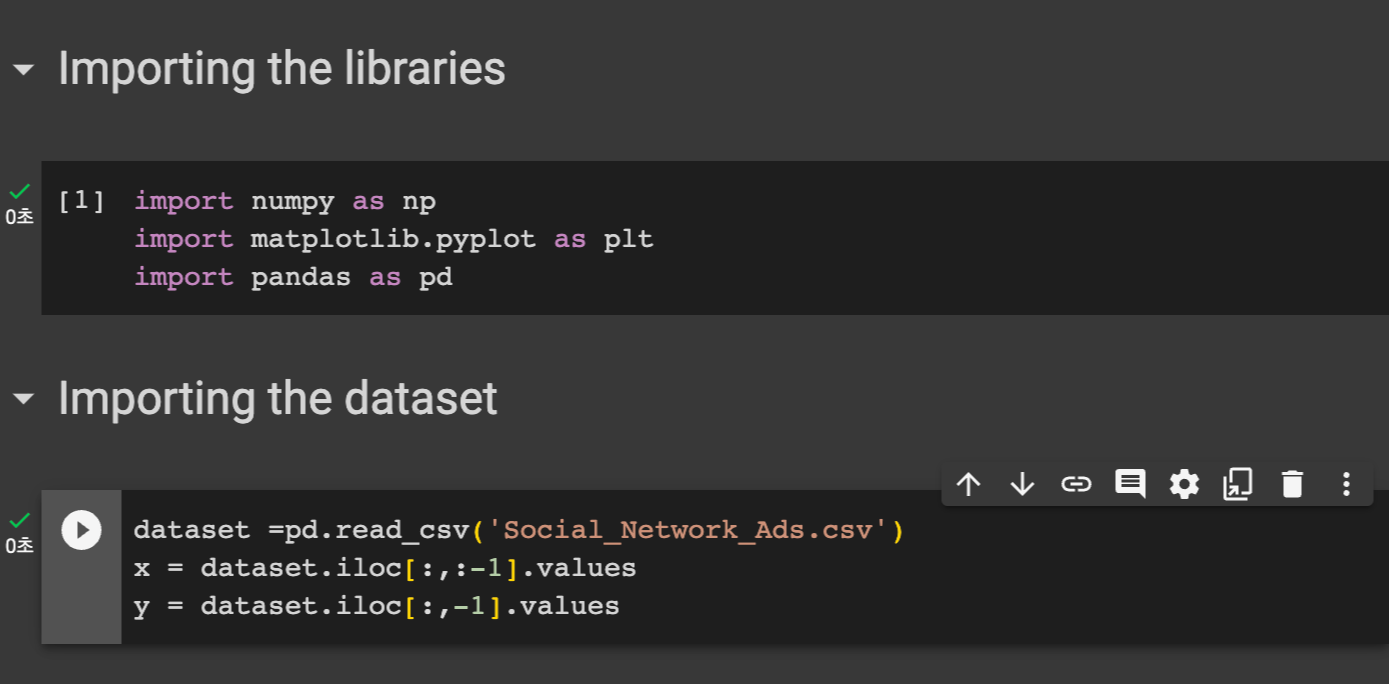
STEP 1) 라이브러리 ,데이터셋 호출

언제나 그랬듯 라이브러리들을 임포트해준다.
numpy, matplotlib, pandas 를 임포트한다.

다음은 우리의 데이터셋을 불러온 후 X에는 독립변수, y 에는 종속변수를 담는다.
X = dataset.iloc[:, :-1].values
y = dataset.iloc[:, -1].values
이다. 캡처 찍을때 실수해버렸다..
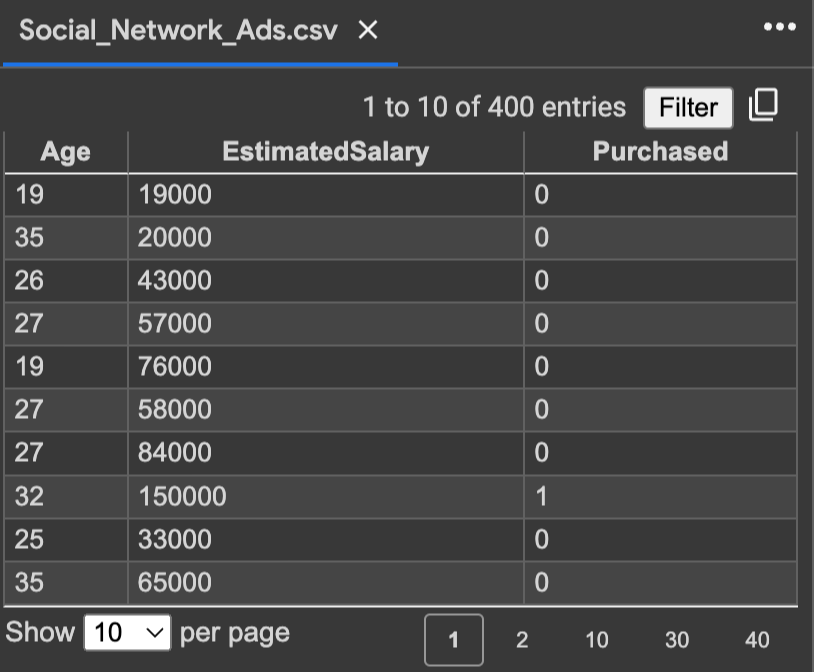
이번 데이터셋은 저번에 사용했던 것으로
나이와 봉급에 따른 SUV 구매여부를 나타낸 표이다.

STEP 2) 데이터 전처리
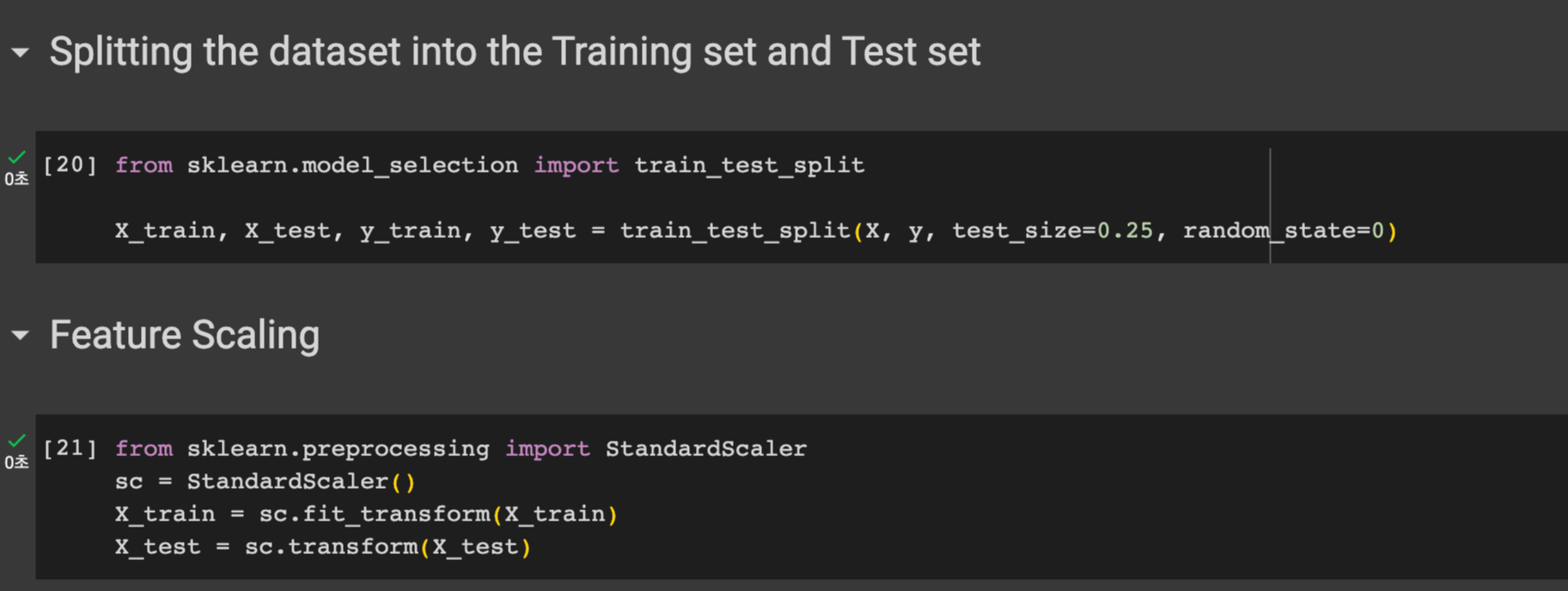
우선 sklearn의 model_selection 모듈에서 train_test_split 를 임포트한다. 이를 통해 훈련 데이터와 테스트 데이터를 분리한다.

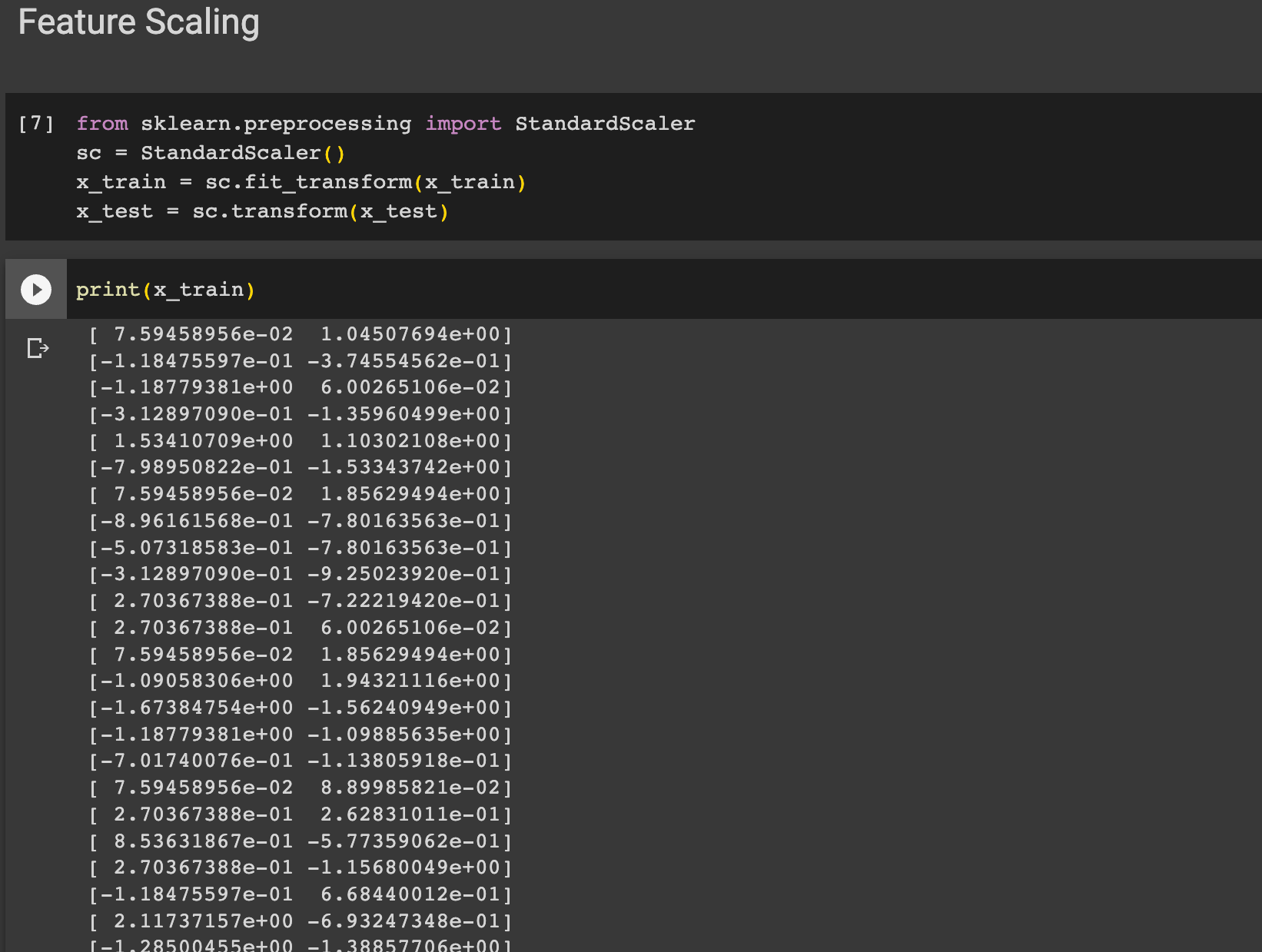
아까 데이터에서 봤듯이 나이는 0-100사이인 반면, 봉급은 매우 높은 수치이다. 이럴때 필요한 데이터 전처리 과정으로 Feature Scaling 이 있다. sklearn에서 preprocessing 모듈에서 StandardScaler 클래스를 임포트한다. 그 후 트레인 데이터에 맞게 변형해준후 테스트 데이터도 변형한다.
STEP 3) 모델 학습
https://scikit-learn.org/stable/modules/generated/sklearn.tree.DecisionTreeClassifier.html
sklearn.tree.DecisionTreeClassifier
Examples using sklearn.tree.DecisionTreeClassifier: Release Highlights for scikit-learn 1.3 Classifier comparison Plot the decision surface of decision trees trained on the iris dataset Post prunin...
scikit-learn.org
sklearn.tree 모듈에서 DecisionTreeClassifier 클래스를 임포트한다.
criterion 은 entropy 로 설정하고 random_state 는 0으로 설정하여 classifier 객체를 만든다.
그 후 X_train, y_train 을 fit하여 훈련시킨다.
criterion 은 우리가 최소화 또는 최대화 시키길 원하는 함수를 말한다. 비용함수 또는 오차함수라고도 말하며 최소화 하고자하는 목적함수를 특별히 칭하는 용어이다.
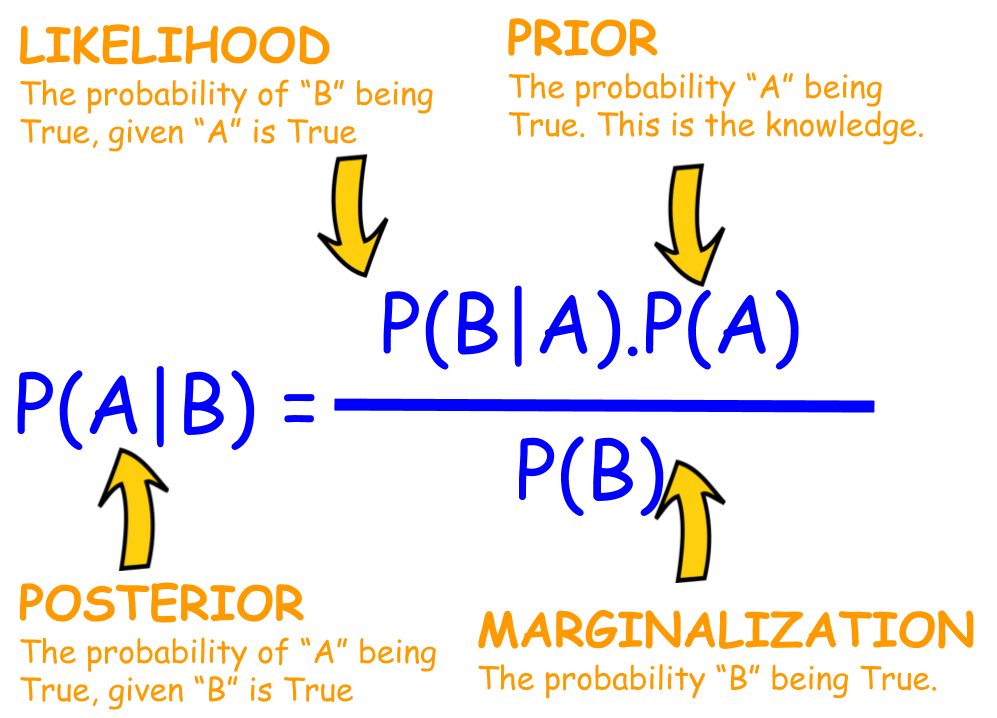
여기서 entropy는 의사결정트리는 가지고 있는 데이터에서 어떤 기준으로 나눴을 때 나누기 전보다 엔트로피가 감소하는 지를 따진다. 만약 감소하면 모델 내부에서는 정보 이득을 얻었다고 본다.
우리는 criterion 을 entropy로 설정했는데 이는 엔트로피를 최소화하고자하는 것이다.

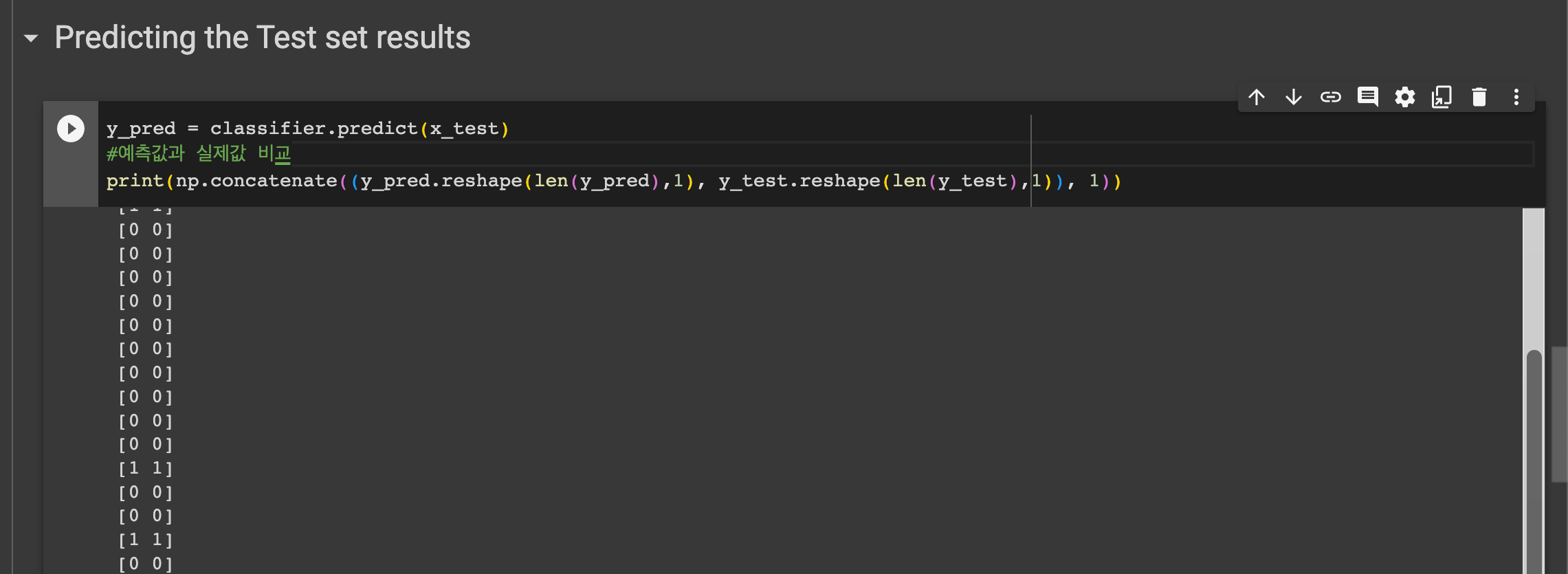
다음은 테스트 결과 예측을 위해
classifier.predict(X_test) 를 통해 테스트 셋에 대해 예측을 한후 y_pred 에 담는다.
STEP 4) 평가하기
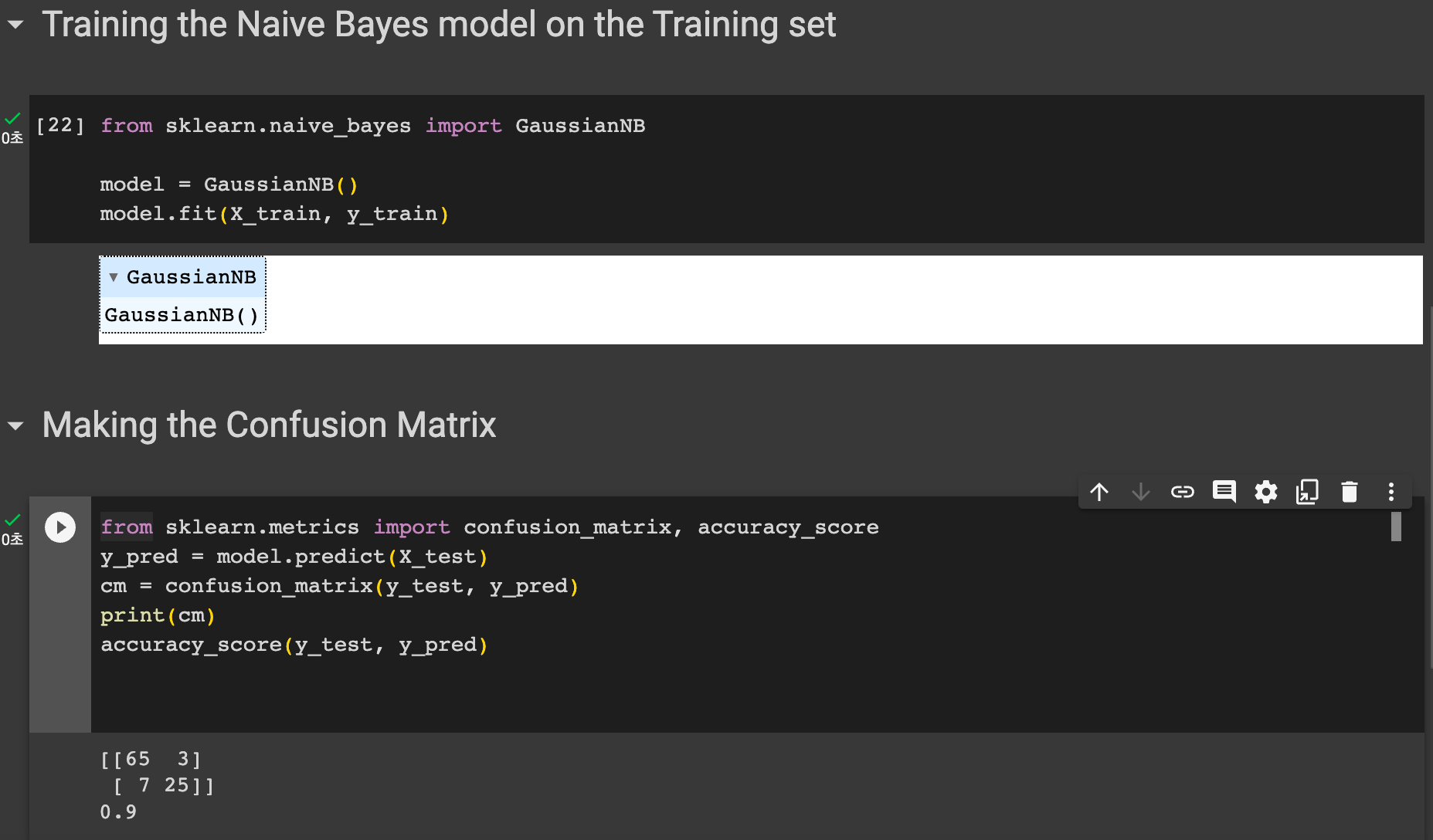
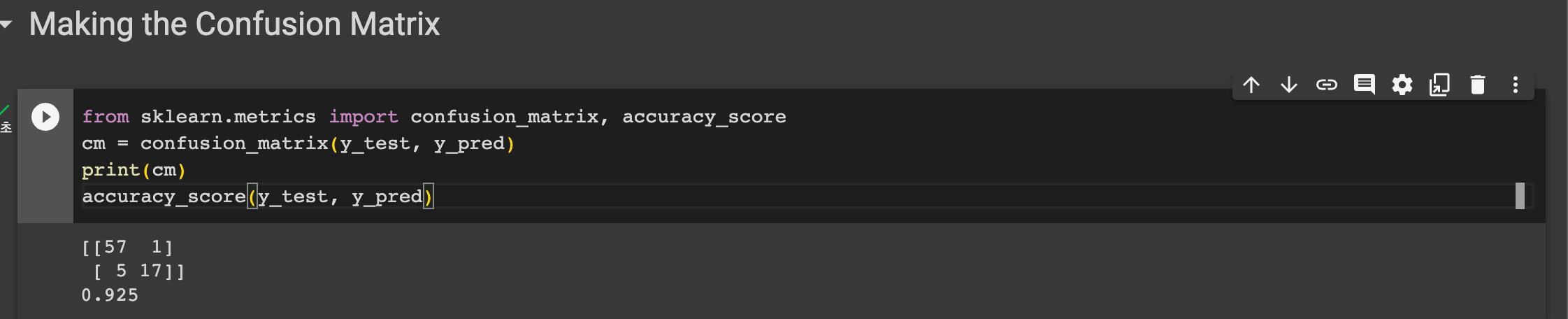
다음은 모델의 정확도를 평가하기 위해 혼잡 행렬을 그려볼 것이다.
sklearn.metrics 모듈에서 confusion_matrix와 accuracy_score 을 임포트한다. 그리고 y_test, y_pred 를 confusion_matrix 의 인자로 담고 출력한다. 다음과 같은 매트릭스를 얻을 수 있었다.
accuracy_score(y_test, y_pred) 를 통해 정확도도 출력해보자

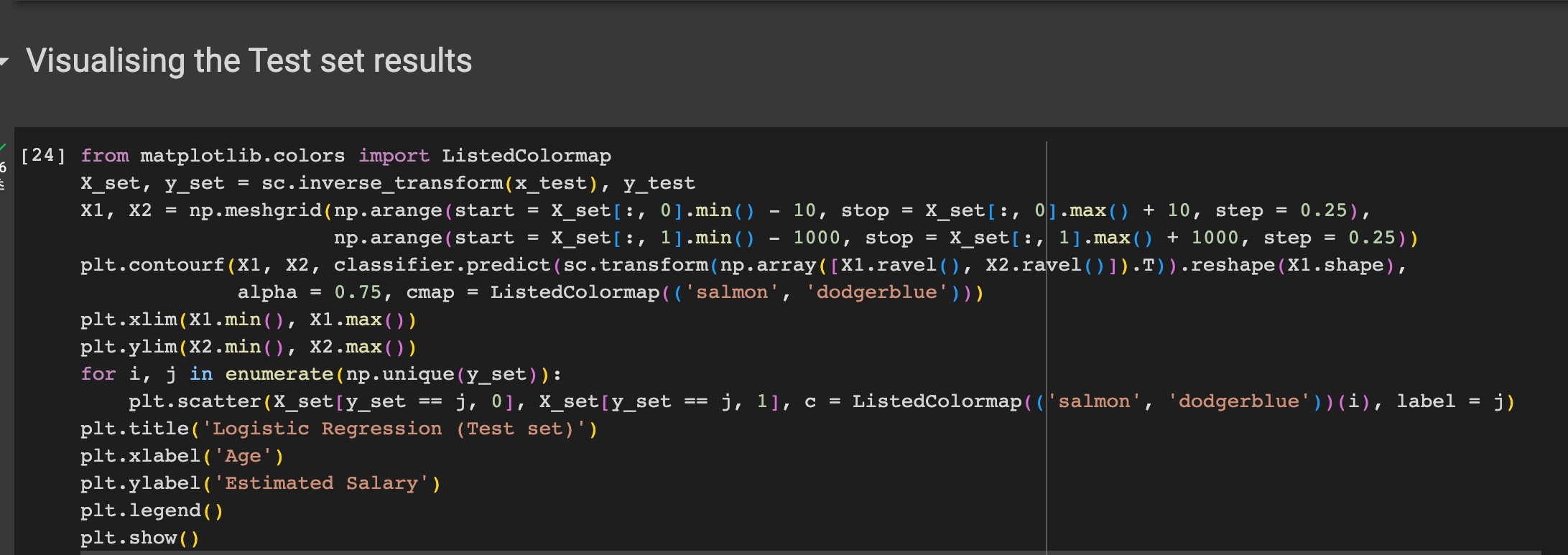
그래프로 모델의 예측값과 실제 밸류를 그려보자

다음과 같은 결과를 얻을 수 있었다.

'기계학습' 카테고리의 다른 글
| [머신러닝] Nonlinear Regression (1) | 2023.10.04 |
|---|---|
| [머신러닝 유데미] Bayesian Classification (0) | 2023.09.28 |
| [기계학습 2] Bayesian Classifier (0) | 2023.09.20 |
| [머신러닝 유데미] Classification introduction / Logistic Regression 실습 (0) | 2023.09.19 |
| [기계학습 1] Introduction / 머신러닝 정의 (0) | 2023.09.13 |