
유데미 강의를 다시 듣기 시작했다.
지난 번에는 Regression 을 배웠고 이제 Classification 이다.
Classification
Classification 은 학습 데이터에 근거해서 새로운 관찰을 얻는 머신러닝 테크닉이다. 이 관찰은 카테고리이다. Regression 에서는
실수 값을 얻는 머신러닝 테크닉이었다.
이 Classification 은 이미지 인식에 사용된다. 사진을 보고 개인지 고양이인지 판단하는 일 같은 것 말이다.
Logistic Regressinon 은 수많은 독립 변수에 근거해서 카테고리의 종속 변수를 예측한다.
예를들어 Age 에 따른 의료 보험 가입 여부를 예측하거나 할 때 사용된다.
Linear Regression 은 예측을 위해 데이터를 통한 선을 그렸었다. Logistic Regression 은 선을 그어서는 구하기 어렵다.


아까 예시에서 독립 변수인 나이와 종속 변수인 보험 구매 여부에 대한 데이터를 통해 학습을 시켜 오른쪽과 같은 Logistic Regression 곡선이 나왔다고 하자. 구매하지 않는다는 0 구매한다는 1의 값이다.
예를 들어 35세와 45세의 보험 구매 여부를 예측할때 35살은 왼쪽 방정식에 의하면 42%이고 45세는 81%로 35세는 구매하지 않을 것이고 45살은 구매할 것으로 예측할 수 있다.
Logistic Regression 은 여러 독립 변수를 가질 수 있다.
Age 뿐만 아니라 소득, 교육수준, 가족인지 싱글인지 와 같은 요소들 말이다.
독립 변수가 많아진다면 Logistic 방정식도 다음처럼 된다.

위 그래프가 데이터에 맞는 곡선인지 어떻게 알 수 있을까?
Maximum Likelihood
Likelihood는 어떤일이 발생할 가능성이다.
Maximum Likilihood 를 통해 모든 가능성 중에 우리의 모델에 가장 적합한 모델을 찾을 수 있다.
아까 예시에서 그래프에 있는 파란점은 보험에 가입한 사람과 연령을 나타내고 빨간점은 가입하지 않은 사람과 연령을 나타낸다.
각각의 확률을 구했을때 19세가 구입할 확률은 0.01이다. 해당 점은 구입하지 않았는데 구입하지 않을 확률은 0.99 가 된다.
이런식으로 모든 점에 대해 구하고
Likelihood 는 해당 점들에 대한 확률을 모두 곱한다.

Likelihood 로 최적의 value 를 얻을 수 있다. Likelihood 를 살펴보며 우리의 모델에 가장 맞는 모델을 찾는다.
Best Curve <= Maximum Likelihood 이다.
실습
Logistic Regression 에 대한 구글 코랩 실습 자료에 들어간다.
먼저 데이터를 살펴보면
Age와 Salary 데이터와 SUV 자동차 구매 여부에 관한 표이다.
우리의 목적은 나이와 추정봉급에 따른 SUV 구매 여부를 예측하는 것이다.
독립변수는 나이와 추정봉급이 되고, 종속 변수가 구매 여부가 된다. 0이 구매하지 않음을 1이 구매했음을 나타낸다.
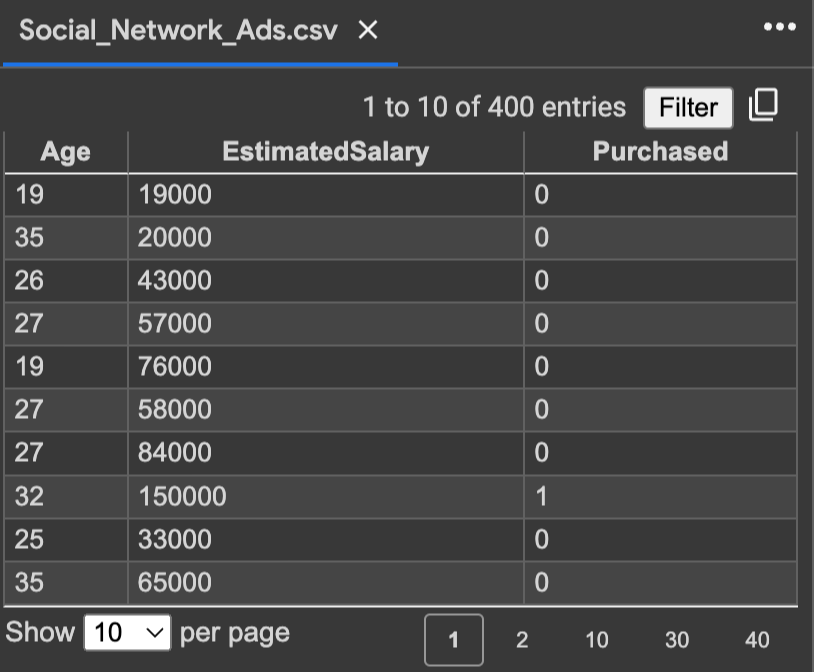
데이터에 대한 observation이 되었다면
구글 코랩으로 들어가자.
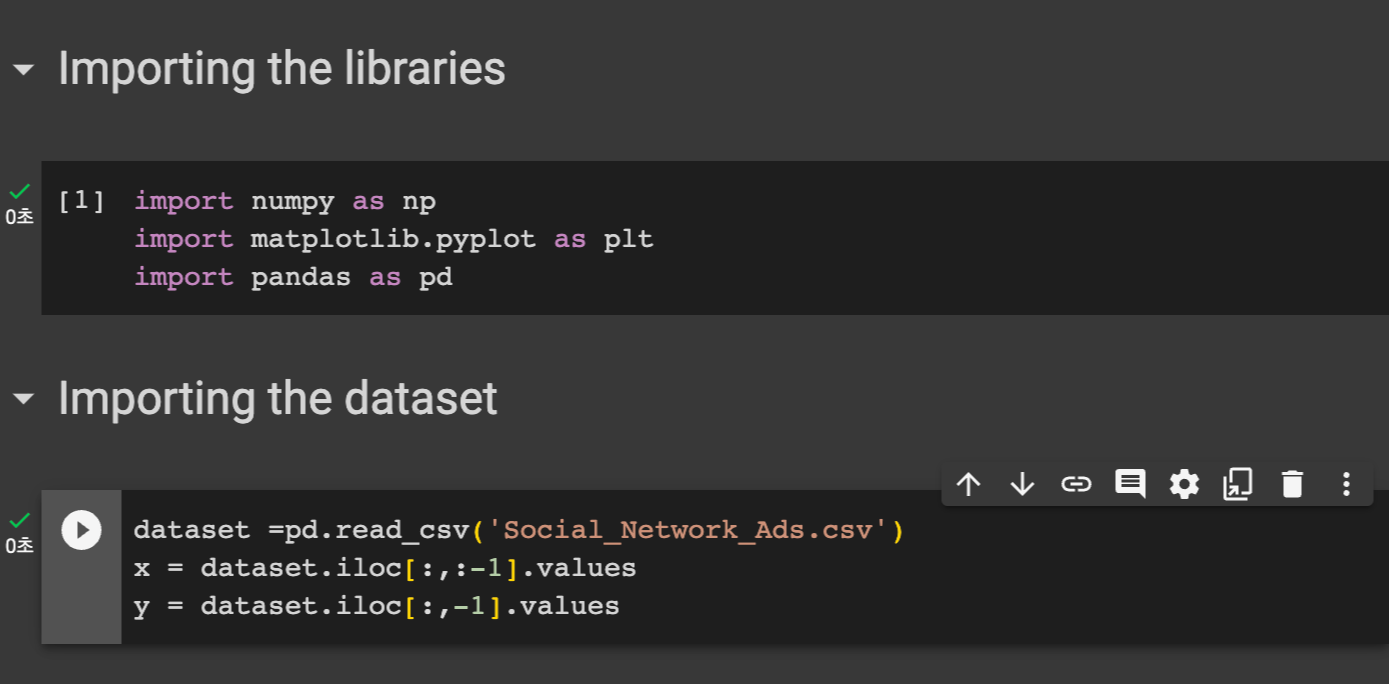
우선 필요한 라이브러리를 임포트해준다. numpy, matplotlib.pyplot , pandas 를 임포트 해주었다.
그 후 우리의 데이터셋을 dataset 변수에 담았다.
pd.read_csv() 메소드를 활용한다.
x 에는 독립 변수들을 담고 y 에는 종속 변수를 담는다.
dataset.iloc[:,:-1].values 는 데이터셋에서 행은 모든 행을, 열은 마지막을 제외한 열을 담는 것을 의미한다. 이게 무엇이냐면
마지막 열에는 종속 변수에 대한 value 들이 존재하므로 이것을 제외하고 다른 독립 변수들의 value 들을 담는 것을 의미한다.
y 에는 마지막 value 들만 담으므로 종속변수 밸류가 담긴 것을 알 수 있다.

다음은 데이터를 트레인 셋과 테스트 셋으로 분류한다. test_size를 0.2 로 하여 전체의 20퍼센트는 테스트셋으로 쓴다.
x_train, x_test, y_train, y_test 에는 해당 메소드를 통해 train , test 값들이 분류되어 들어간다.
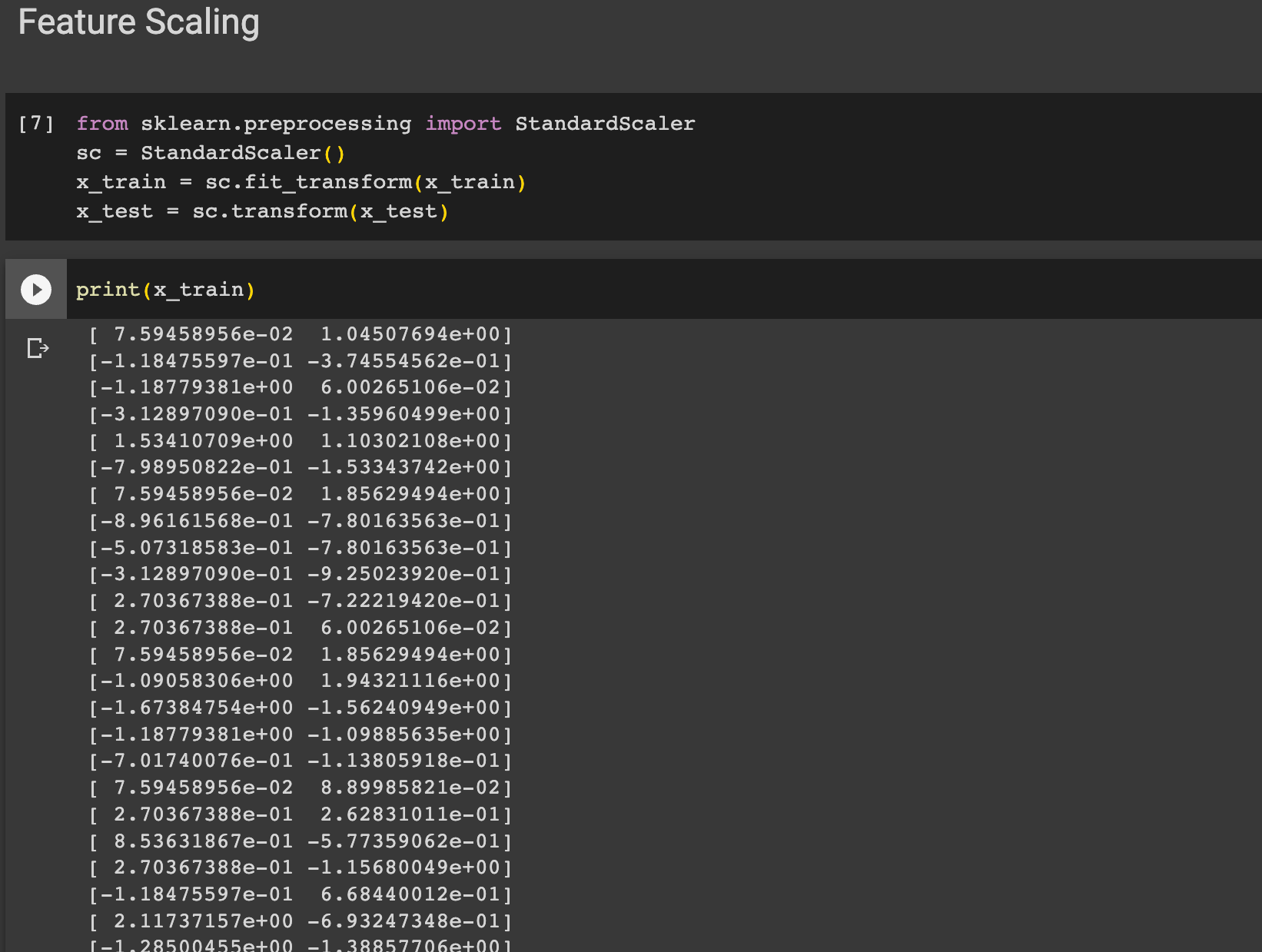
다음은 Feature Scaling 을 해주었다. 이 과정은 데이터의 특징이나 독립 변수의 구간을 표준화해준다. 우리의 데이터들을 보면
Age는 0에서 100 사이지만 봉급은 만단위이다.
이렇게 10살에서 20살 차이와 돈이 10,000원에서 10,020원이 되는 것은 천지차이이다. 따라서 표준화 과정이 필요하다.
sklearn.preprocessing 에서 StandardScaler 를 임포트해준후 x_train 을 표준화 시킨 값으로 다시 넣어준다.
x_train 에는 독립 변수들만 들어가고 둘 다 표준화가 필요하므로 따로 인덱싱은 해주지 않는다.
print(x_train)을 통해 확인한 결과 값이 Featrue Scaling 이 잘 된것을 확인할 수 있다.
다음은 Logistic Regression 모델로 훈련시켜야한다. 이때 사용하는게 scikit-learn 인데 다음 사이트에서 확인할 수 있다.
https://scikit-learn.org/stable/
scikit-learn: machine learning in Python — scikit-learn 1.3.0 documentation
Model selection Comparing, validating and choosing parameters and models. Applications: Improved accuracy via parameter tuning Algorithms: grid search, cross validation, metrics, and more...
scikit-learn.org
sklearn.linear_model 모듈에서 LogisticRegression 클래스를 임포트해서 객체를 생성한다.
그 후 모델에 데이터를 넣어서 훈련시킨다. ( classifier.fit(x_train, y_train) 사용 )
우리가 훈련시킨 모델로 훈련을 시키자

이제 예측을 해보자 다만 주의할 점으로는 데이터를 담을때 feature scaling 을 해줘야한다.
sc.transform을 통해 해줬다.

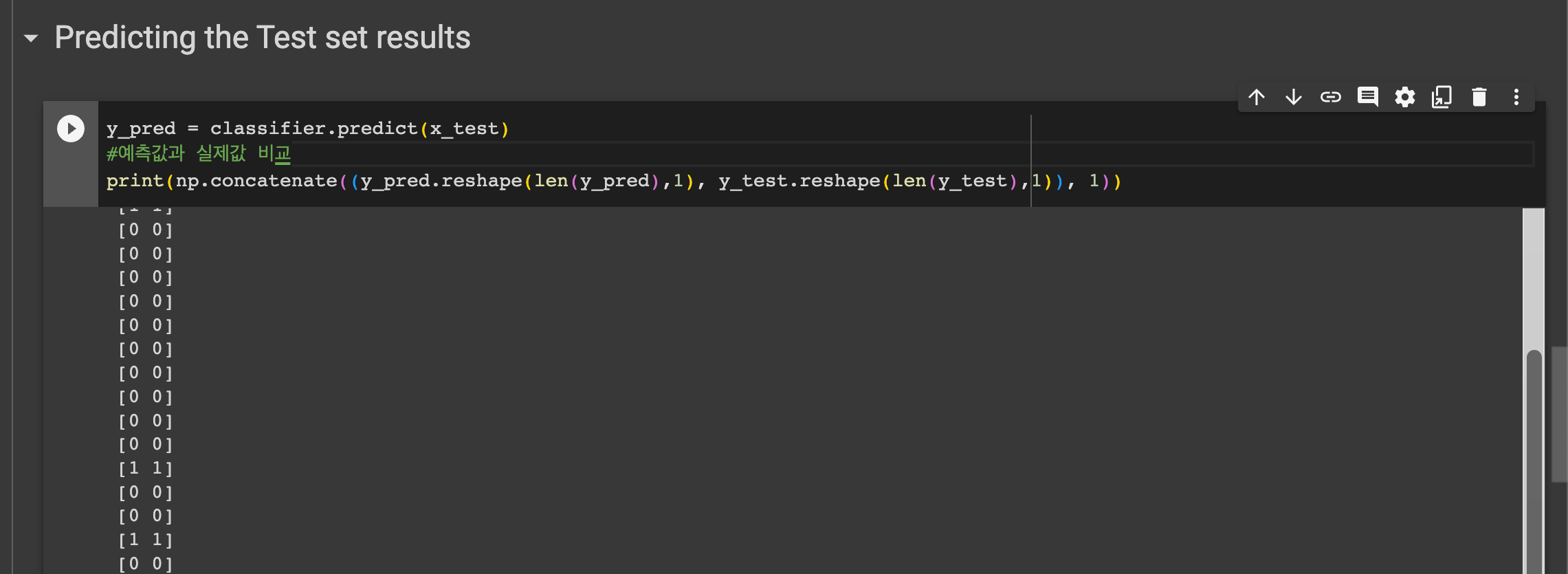
훈련한 모델을 예측값과 실제값을 비교해주자.
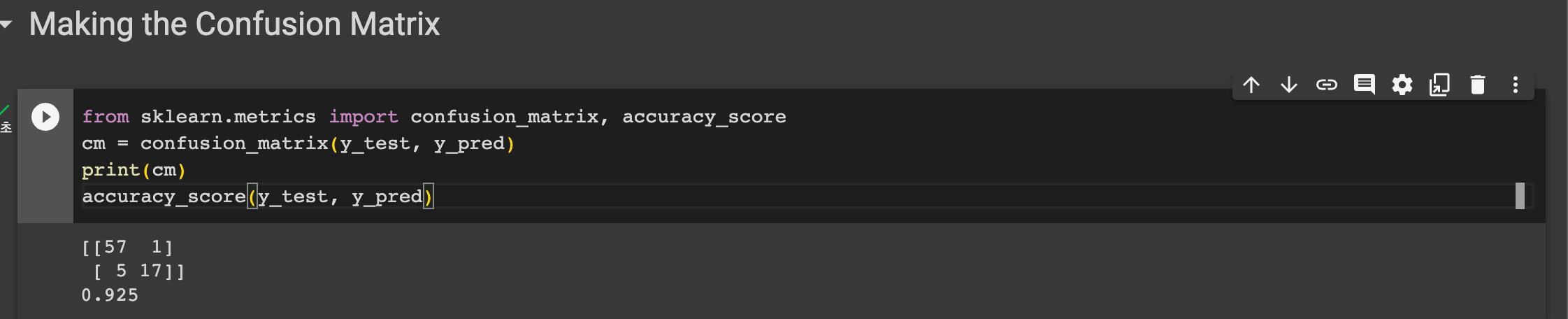
그 후 confusion matrix 를 만들고 정확도를 계산하였다. 정확도는 0.925 가 나왔다. 시험세트의 약 92퍼센트가 정확했다는 의미이다.
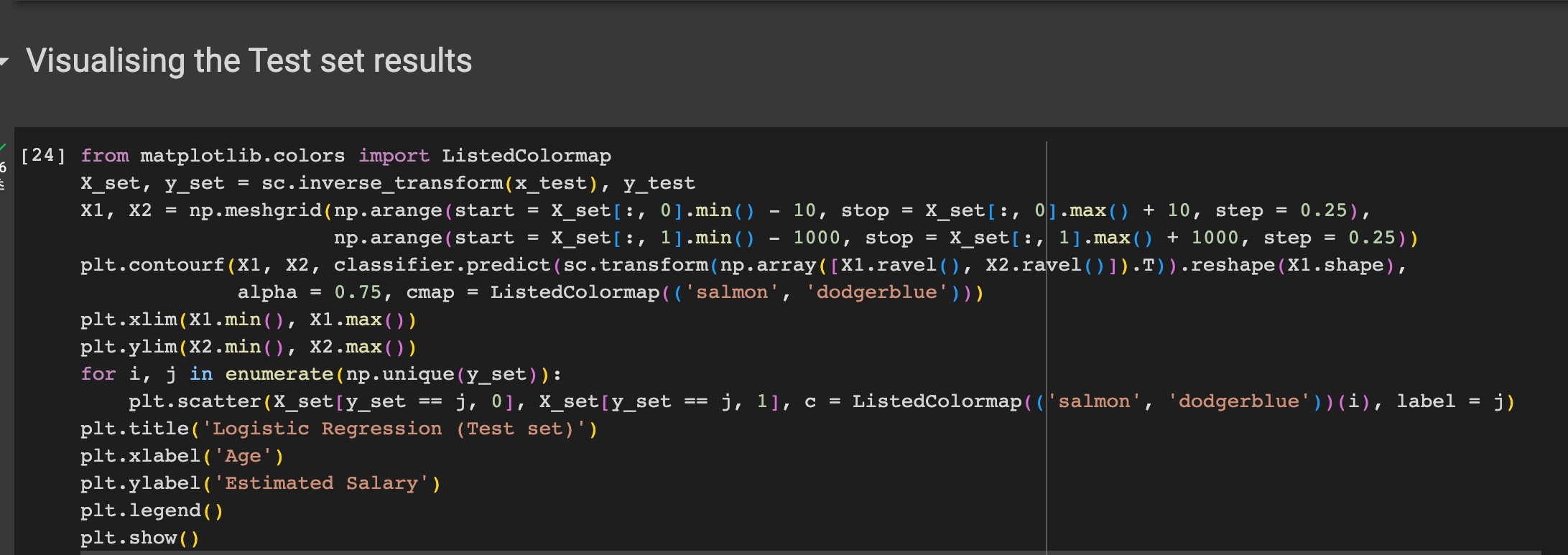
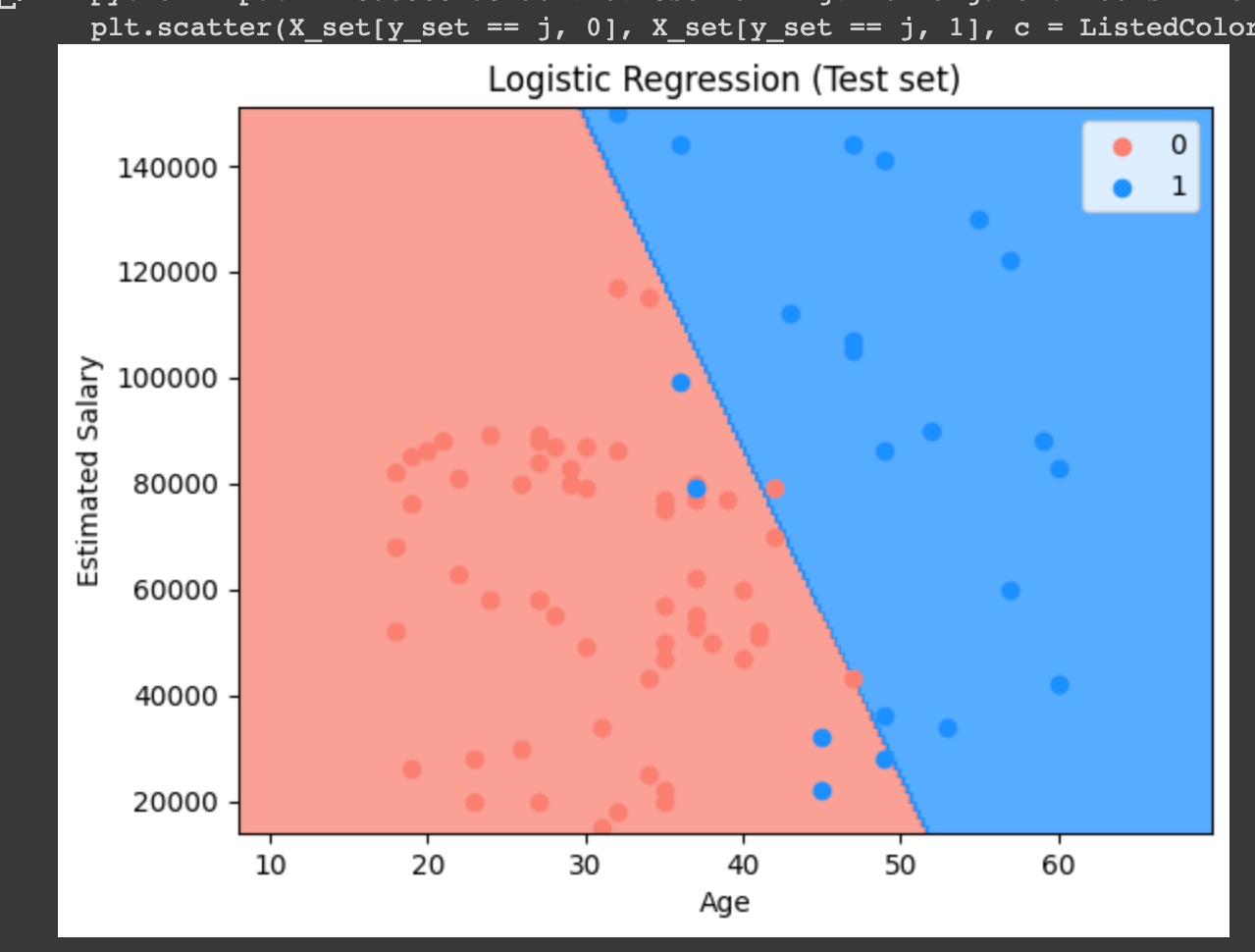
비주얼라이징 하였다.
'기계학습' 카테고리의 다른 글
| [머신러닝 유데미] Decision Tree (0) | 2023.10.05 |
|---|---|
| [머신러닝] Nonlinear Regression (1) | 2023.10.04 |
| [머신러닝 유데미] Bayesian Classification (0) | 2023.09.28 |
| [기계학습 2] Bayesian Classifier (0) | 2023.09.20 |
| [기계학습 1] Introduction / 머신러닝 정의 (0) | 2023.09.13 |